Data Distribution Service (DDS) specification from Object Management Group (OMG) is a data-centric publish/subscribe (DCPS) messaging standard for integrating distributed real-time applications. Here’s how process replication can increase a system’s fault tolerance.
Data Distribution Service (DDS) specification from Object Management Group (OMG) is often used to build mission critical systems consisting of multiple components executing simultaneously and collaborating to achieve a certain task. In such systems, there are usually several components that are critically important for the overall functioning. Those components require extra attention when designing the system to ensure that the likelihood of them failing is minimized. Its focus on reliability, availability and efficiency make the DDS infrastructure particularly suitable to connect the plant floor with other areas of the enterprise.
DDS provides advanced features that help achieve such goals. While there are many methods, fault tolerance for failing publishing applications or machines can be achieved by means of active process replication.
Guiding example
For the purpose of illustrating the theory here with an example, the use case of the simple distributed finite state machine (FSM) is described. The FSM consists of a few components: a Master Participant, a Worker Participant, and a Manager. The Observer component, not essential for the functionality of the pattern, is passively observing only. This example focuses on the interaction between the Manager and the Observer.
Let’s assume that the Manager is the most critical process in the pattern, which is likely to be the case, especially if the pattern is expanded to support multiple Masters and Workers. The most obvious way to make the Manager component more robust is by running multiple processes simultaneously, all with the same responsibility. With that approach, the Manager component is defined as a conceptual item that may consist of multiple, simultaneously running application processes. For the sake of simplicity, the collection of those processes is referred to as the Manager component. Note that those could be executing in a distributed fashion on multiple machines.
Active process replication
Simultaneously running multiple Manager processes with the same purpose will decrease the likelihood that the Manager component will break down completely. DDS allows for adding and removing participants on the fly without requiring configuration changes, so the basic concept of process replication is supported. Still, there are multiple options from which to choose.
Plain process replication
The most basic approach is to run multiple, identical Manager applications. Each acts the same, receiving the same transition requests and publishing the same state updates in response. As a consequence, applications observing the state machine will see multiple instances of that state machine simultaneously. This approach requires a minor adjustment to the data-model to allow multiple task instances to exist side-by-side. This is achieved by adding a key attribute that identifies the originating Manager application.
An advantage to this approach is its low complexity; just replicating everything is an approach everybody understands. There is no impact on the Manager application code, and all participants remain completely decoupled from each other. Additionally, the mechanism does not rely on any built-in replication mechanism from the middleware. This could be considered an advantage as well, because the developer now has every aspect of the replication process under control.
On the other hand, that latter argument could be seen as a disadvantage. Requiring all Observers of the state machine to be able to deal with multiple, identical versions simultaneously does have an impact on the application code and introduces an extra burden on the application developer. Also, the number of instances an instance state updates scales linearly with the number of Manager processes. For this particular state machine example that is not that big of a deal, but in the general case, it could have a significant impact on network bandwidth consumption and memory usage.
Process replication, writer-side peer awareness
To avoid disadvantages, another option is to make Manager processes aware of each other at the application level. If all Manager processes know which other Manager processes are currently participating in the infrastructure, then they all could decide for themselves, according to a system-wide consistent selection algorithm, which of the replicated Manager processes is the currently active one. All Manager processes would be participating in the pattern and updating the relevant states accordingly—but only the active Manager would actually be communicating those updates to the data-space. If the active Manager leaves the system for some reason, then the remaining Manager processes need to decide for themselves whether or not they are the new active Manager and adjust their behavior accordingly.
DDS supports the necessary features to implement this approach. By subscribing to so-called built-in Topics, applications can be made aware of other DDS Entities in the cloud. This kind of subscription also can notify the application of lost liveliness or destruction of each of these Entities. Those two aspects combined are sufficient for this example.
This approach has no application-level impact on subscribing components in the system and, consequently, they do not require code changes. This kind of replication also does not consume any extra bandwidth or resources, as plain replication does.
There is some impact at the application level for the Manager processes. The mechanism of peer-awareness and leader selection has to be created. This is not trivial, and the impact of bugs in that piece of code could be high. (It could lead to none of the processes stepping up as the leader!)
Process replication, exclusive ownership
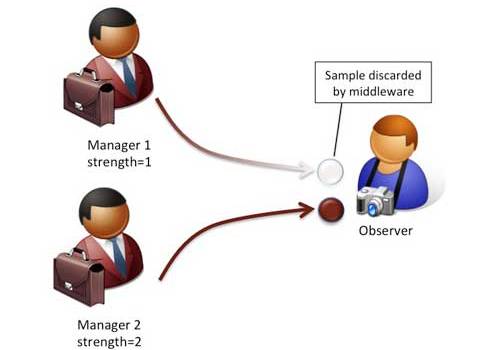
The last option here takes advantage of a native DDS feature called exclusive ownership. Normally, DDS allows multiple publishers to update the same data-item simultaneously. This behavior is called shared ownership, and it is the default setting for the ownership quality of service (QoS) setting. If the nondefault setting, called exclusive ownership, is selected, the infrastructure will make one of the publishers the owner of the data-item—at any time, only the owner of the data-item can update its state. For this leader selection, another policy called ownership strength can be adjusted. This integer value will be inspected by the middleware to identify the current leader at any time, that is, the publisher with the highest ownership strength. This selection is done consistently through the system.
Other than selecting the right QoS, this solution is transparent to all system components. The different Manager processes are unaware of each other and execute their tasks independently. Similarly, the subscribing components do not (have to) know that in fact, multiple publishers are present in the system. Everything needed to achieve the required functionality is handled within the middleware. As a consequence, no extra code has to be added, nor tested, nor maintained.
Exclusive ownership functionality is described in the DDS specification and was designed with the mechanism of process replication in mind. In that sense, it is not a surprise that this solution is usually the best fit. The specification does not indicate how this functionality should be achieved by the middleware; that is left up to the product vendors. However, it is good to know that typically, for optimal robustness, implementations do send data over the wire for each of the active publishers, and the leader selection takes place at the receiver side. This means that the feature does result in extra networking traffic.
Recovering from faults
Process replication is an important aspect of increasing fault tolerance in a system. However, there is more to it. If a system, by virtue of the process replication, can continue after a fault, then it will have entered a stage in which it is less fault-tolerant simply because one of the replicating processes is gone. It is still essential that the system recovers as quickly as possible from the fault and returns to the fault-tolerant state. In our example, this means that the failing Manager process will have to restart, obtain the current state of all task data-items, and start participating in the pattern again. DDS can help make the task of recovery easier as well.
– About the author: Reinier Torenbeek is a systems architect at Real-Time Innovations (RTI). He has experience with all aspects of architecting, designing, and building distributed, real-time systems. He has been a developer of real-time publish/subscribe middleware for several years. In the field, he has worked with customers in many kinds of domains. He has been involved in a wide range of middleware software activities for 15 years. Currently, he serves as a consultant for customers creating their systems using the RTI Connext product suite, focusing on commercial and industrial automation applications. Edited by Mark T. Hoske, content manager, CFE Media, Control Engineering, [email protected].
See this article at www.controleng.com/archive for more about the author.