When it’s easy to implement alarms, too many often make the list. Alarm rationalization helps you control and optimize the selection. This is the March Control Engineering cover story. See tables, examples.
We’ve seen it before: poorly designed alarm systems have caused operators to miss critical alarms or to respond incorrectly, leading to unplanned shutdowns, reduced product quality, damaged assets, or worse. Reductions in operating staff and the corresponding increase in process responsibility for each operator (more loops per operator) have contributed to these issues.
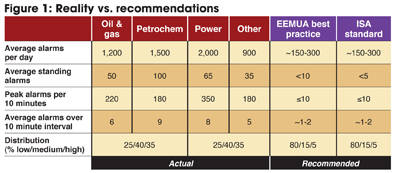
The biggest culprit, however, has been the application of technology in modern control systems. In the days of hardwired controls and alarms (the “good old days” to some), engineers had to justify the need for each alarm that went on the panel because there was a real cost of around $1,000 per alarm and limited space on the panel. Since modern control systems come pre-engineered with alarm conditions galore, alarms are now often mistakenly considered free. There is, therefore, little or no incentive to justify alarms or minimize their number. No one wants to be blamed for not providing an alarm, so many are motivated to enable all of the alarm conditions provided by the system. As shown in Figure 1 below, this has led to alarm overload in the control room, nuisance alarms, alarm floods, and incorrectly prioritized alarms, all of which diminish the operator’s effectiveness.
Some basics
A well-functioning alarm system allows the operator to run the process close to its ideal operating point and keep it running safely. The first step in designing such a system is to establish the criteria for an alarm and document it in an alarm philosophy document using the following definitions:
Alarm: An audible and/or visible means of indicating to the operator an equipment malfunction, process deviation, or abnormal condition requiring a defined response. It follows that adequate time must be allowed for the operator to carry out that response. In addition, each alarm should alert, inform, and guide; and each alarm presented to the operator should be useful and relevant [Ref ISA-18.2 and EEMUA 191]. This means if the operator does not need to respond, there should not be an alarm.
Alarm philosophy document (APD): The document that establishes the standards for how a company or site will address all aspects of alarm management, including design, operations, and maintenance. It contains the definition/criteria for determining what should be an alarm, in addition to the rules for rationalization such as how to prioritize alarms, determine their setpoints, and classify them. The alarm philosophy document must be in place before rationalization can begin.
The term “alarm” is often used to identify candidate alarms as well as those that have completed rationalization. For clarity in this discussion we’ll make this distinction:
A candidate alarm is one being considered for inclusion in the alarm system. It can already exist (brownfield system) or be a proposed/potential alarm for a greenfield or brownfield system.
The term “alarm” will designate a rationalized alarm, one that has been evaluated against the APD and found to meet the necessary criteria.
Beginning the process
Rationalization is the process in which a multidisciplinary team reviews each candidate alarm to ensure that it is justified and meets the criteria for being an alarm as documented in the APD. The goal is an alarm system in which the right alarm is delivered to the operator at the right time with the right importance and the right information.
Rationalization is one of the stages of the alarm management lifecycle defined in ISA-18.2. It is often called documentation and rationalization (D+R), because all this information should be properly documented in a master alarm database (MADB). Alarm management tools are available to aid in this effort. An effective tool can significantly reduce the time to complete the overall process, both saving money and reducing the time commitment of key personnel.
To begin, form a rationalization team. The team should include three or four core members plus a roster of part-time members who can offer specific expertise. An alarm management expert should serve as facilitator. A sample team is shown below [Ref ISA-18.2 TR2].
Full time:
- Production and/or process engineer(s) familiar with the process, economics, and control system;
- Operator(s) with a deep knowledge of the process and control system experience;
- Process control and instrument engineer; and
- Alarm management facilitator.
One of these will usually be selected as scribe.
Part time as needed:
- Safety/risk management and environmental engineers;
- Maintenance/equipment reliability;
- Instrumentation/analyzer specialists; and
- Management (kick-off).
The team then gathers the documentation required to conduct the review of candidate alarms such as P+IDs, HAZOPs, SIL assessments, operating procedures, and, most importantly, the APD. Then begins the nitty-gritty of the rationalization process, a systematic walk through the steps below for each candidate.
Select and review candidates
Candidate alarms may be selected for review one at a time or as groups where there are similarities. The selection order should follow a logical sequence, typically dictated by the arrangement of the equipment within the process. This allows previous design results to be reused and reapplied.
The first step of the review is to determine whether the candidate meets the fundamental criteria documented in the alarm philosophy, such as:
- Does it indicate a malfunction, deviation, or undesirable condition;
- Does it require a timely operator action in order to avoid defined consequences;
- Is it unique, or are there other alarms that indicate the same condition; and
- Is it the best indicator of the root cause of the undesirable situation?
On operator action: Valid operator actions such as starting a backup pump or opening a valve are designed to change the behavior of the process, while simply acknowledging the alarm or writing it down in a log do not. If an operator action cannot be defined, then the candidate alarm condition is not valid.
On uniqueness: If candidate alarm conditions share the same operator action, then this may indicate redundant alarms. One method of determining whether both high and high-high tank level conditions are valid is to analyze the operator action for each one. If the operator’s response to the high level (reduce the inlet flow) is different in kind or degree from the high-high level (stop the inlet flow), then both conditions may be warranted.
Candidate alarms that don’t pass the criteria are marked for decommissioning or removal from the alarm system. This weeds out candidates that are not necessary or justified. Candidates that pass this criteria move on to the next step, which is to determine their priority.
Determine priority
Alarm priority helps the operator determine which alarm to respond to first and is, therefore, critical to safe and effective control of the process. It is commonly divided into three or four levels with labels such as emergency or critical, high, medium, and low to facilitate operator response. Priority is determined through analysis of two factors: the severity of the consequences of inaction and the urgency. These are combined into an alarm prioritization matrix that is documented in the APD. Table 1 shows a simple illustration. In rationalization, each candidate alarm is evaluated using the matrix from the APD to determine its priority. Modern alarm management tools make this process fairly straightforward.
To begin, it is necessary to identify the direct (proximate) consequences from failing to manage the candidate alarm and their severity. It is important to evaluate only the direct consequences, not what could happen based upon a series of failures. For example, the potential consequences of a safety-critical alarm might be tripping a safety instrumented system, not the hazardous event itself.
If a consequence of inaction cannot be identified, then the candidate alarm should be removed. For example, if the only direct consequence of a high level alarm is triggering a high-high level alarm, then the high alarm may not be needed.
Next, the urgency, which is defined as the time the operator has to respond, must be estimated. Time to respond can represent the time before the operator must begin his or her response, or the allowable time from the activation of the alarm until the last moment that the operator’s action will prevent the consequence.
If the amount of time is too long or unacceptably short, the candidate alarm should be redesigned or the condition should be handled outside of the alarm system.
While matrices from various sources will differ, Table 1 illustrates the concept. Priority is identified by the intersection of the column with the most severe consequence and the row with its estimated urgency. The rationalization team can choose to accept or reject the priority determined from the matrix. The priority and rationale for selection are recorded in the MADB.
Determine the setpoint
The setpoint is the value or logical condition at which an alarm is designed to activate and annunciate to the operator. It must be defined far enough from the consequence threshold to allow time for the operator to take corrective action and for the process to respond, including an acceptable safety margin. It should also allow enough distance from normal operating conditions that the alarm is not triggered as a result of normal process variation.
In a brownfield system, operating experience can often be used to judge if the existing setpoint provides an acceptable amount of time. If so, the existing setpoint is accepted. If the judgment is that the setpoint is not acceptable, or if it is a greenfield system, then it is determined from an evaluation of the process dynamics. Information guiding this should be in the APD. The setpoint and rationale for its selection are recorded in the MADB.
A common mistake in designing alarms is to configure alarm setpoints based on rules of thumb relative to the engineering range. An example is configuring the setpoints for high-high, high, low, and low-low as 90%, 80%, 20%, and 10% of range, respectively. This can result in alarm setpoints that do not properly take into account the time the operator has to respond, the process variable’s rate of change, the consequence threshold, or the process deadtime.
Other documentation
Design: Rationalization includes documentation of alarm parameters besides priority and setpoint. Careful consideration of these parameters can result in greatly improved alarm system performance. For example, proper application of deadband and alarm delays can minimize chattering alarms, a type of nuisance alarm, as well as prevent problems during installation and commissioning. Alarm deadband is a function used to reduce the number of times an alarm triggers for a given abnormal condition, which ideally would be only once. It prevents an alarm from returning to normal until the alarm condition is cleared by the deadband.
Another example is using advanced alarming, such as alarm suppression, to ensure that alarms are relevant. Alarm suppression techniques prevent the annunciation of an alarm to the operator when the base alarm condition is present but not relevant. For example, an alarm indicating low suction pressure to a pump that is not running could be suppressed. Other examples of suppression techniques include alarm flood suppression, where alarms are suppressed during specific unplanned scenarios, and state-based suppression when alarms are suppressed based on the operating state of the plant. In some state-based alarming scenario cases, alarm setpoints should be set differently based on the state of the process.
Operator response: As shown in Table 2, rationalization also includes documentation designed to improve operator response, including probable causes of alarm activation, procedures for corrective action (the operator’s response), and verification procedures to confirm that the alarm condition is real (not a false alarm). All this documented information should be made available to operators to help them diagnose and respond to alarms. Alarm response procedures can be used for operator training and can be integrated into the HMI (human machine interface) to provide operators with online access to this information.
Management practices: Finally, rationalization includes classification to identify groups of alarms with similar characteristics and common requirements for training, testing, documentation, management of change, or data retention. This makes management and administration easier. It also provides extra visibility to those alarms which require special treatment such as those that are environmentally critical, provide risk reduction as part of a layer of protection analysis, or are OSHA PSM critical.
Benefits of alarm rationalization
When it comes to alarms, more is not better. Successful rationalization activity will yield an optimum set of alarms that are needed to keep the process safe and in the normal operating range. When executed properly, rationalization will:
- Reduce alarm load on the operator;
- Reduce the chance of missing critical alarms;
- Remove nuisance alarms (e.g., chattering, fleeting, or stale alarms);
- Eliminate redundant alarms;
- Insure that alarms are properly prioritized for correct action;
- Improve operator response–quicker, more consistent, and more effective;
- Increase system integrity–improve operator trust of alarm system;
- Optimize the risk reduction of alarms used as a safety layer of protection; and
- Lay the groundwork for continued process improvement.
Not only will the result be that the right alarm is delivered to the operator at the right time with the right importance and the right information, but an effective rationalization will also help comply with industry standards such as ISA-18.2, which is expected to be considered as “good engineering practice” by insurance companies and regulatory agencies in the near future.
Todd Stauffer is an alarm management consultant for exida. Reach him at tstauffer(at)exida.com. John Bogdan is principal consultant for J Bogdan Consulting. Reach him at jbogdan(at)jbogdanconsulting.com. Susan Booth is a technical writer for J Bogdan Consulting.
For more information, visit:
Rationalization example
Let’s look at a simple example to see how the rationalization process works. Consider a storage tank with an overflow line, all contained within a dike. The overflow line is sized to handle the maximum flow into the tank, and the dike area volume is sufficient to contain the entire contents of the tank safely. An automated trip shuts off the flow into the tank before the level reaches the overflow line. This automated trip provides enough risk reduction so that no additional layers of protection are required. The number and type of level measurements are irrelevant for the purposes of this discussion; however, we can assume that the level measurement is accurate and reliable. During the design of the control system, three candidate alarms were proposed:
- A high level alarm activated below the automated trip;
- A high-high level alarm at the trip; and
- A high-high-high level alarm between the trip and overflow.
Let’s rationalize each of these candidate alarms in turn.
High level: This candidate alarm is both relevant and unique. It is important that the operator be alerted to an impending trip, and level is the single, best measurement to detect it. The consequence of failing to manage the high alarm is that the level will continue to increase until the automated trip is activated. Since the automated trip should be designed to stop the flow into the tank safely, the only impact to the process is the upset caused by that stoppage. Referring to the prioritization matrix (Table 1), there are no safety or environmental impacts. Assuming that the financial impact to the business of the flow stoppage is minor (less than $50,000) and that the operator has more than five minutes to respond, the priority of this alarm would be low. Typical corrective actions would be to reduce the flow into the tank, divert the flow to a different tank, and/or increase the outflow from the tank.
High-high level (trip): The automated trip is a direct result of failing to manage the high level alarm. It does not have any consequences that are different from the high level alarm, so it is not unique. In addition, it does not provide any time for the operator to respond. Thus, it fails on two counts to meet the criteria for an alarm. This candidate alarm should be rejected for inclusion in the alarm system.
High-high-high level: While the high-high-high level is a result of failing to manage the high alarm, it is not the direct result because failure of the automated trip is also required to activate it. Therefore, you cannot automatically deduce that it has the same consequences. In fact, it does not have the same consequences, and it requires different corrective actions. This candidate alarm indicates the failure of the automated trip system, so it is clearly relevant. However, it may not be the best means to detect this failure. Other methods such as valve limit switches, pump run statuses, or flow measurements may provide an earlier indication of the failure. If any of those are available, they should be used instead of this proposed alarm. But for the sake of argument, we’ll assume that they are not available. The consequence of failing to manage this alarm is that the level will continue to increase until the tank overflows into the contained area. Referring again to the prioritization matrix (Table 1), it is unlikely that there would be a serious safety impact. However, there would be both an environmental and a financial consequence requiring notifications and replacing lost product. Based on how quickly the operator response needs to be, rapid or immediate, the priority of this alarm would be medium or high. The corrective actions for this alarm would be different from those of the high alarm and the automated trip (they were obviously ineffective or failed) and would include more aggressive actions to stop flow into the tank.
For this situation, assuming other methods of detecting trip failure are not available, the high and high-high-high level alarms would move on in the rationalization process and, ultimately, be included in the alarm system.
Common alarm performance issues that can be addressed via rationalization are shown in Table 2.



