Manufacturing IT, MES
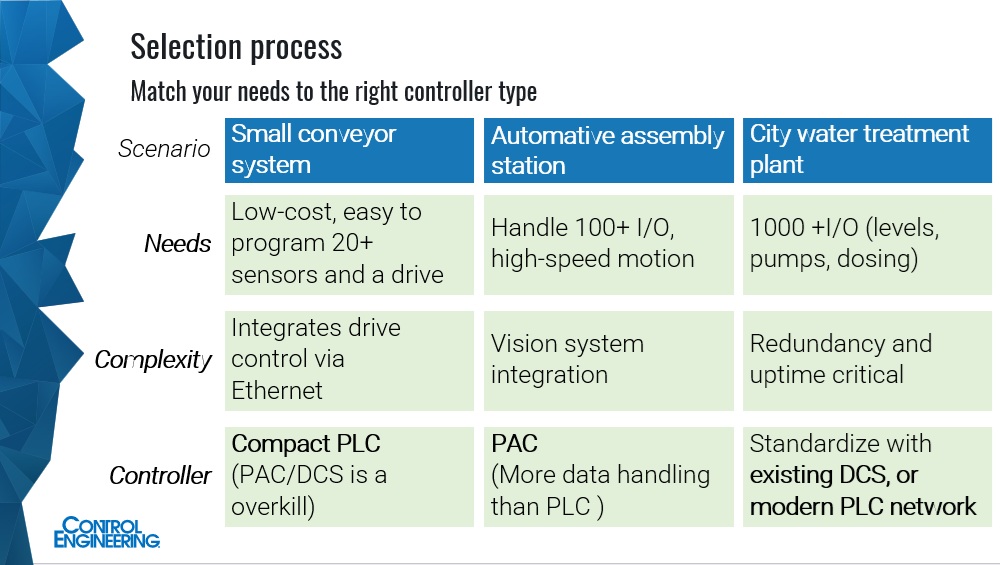
Controllers
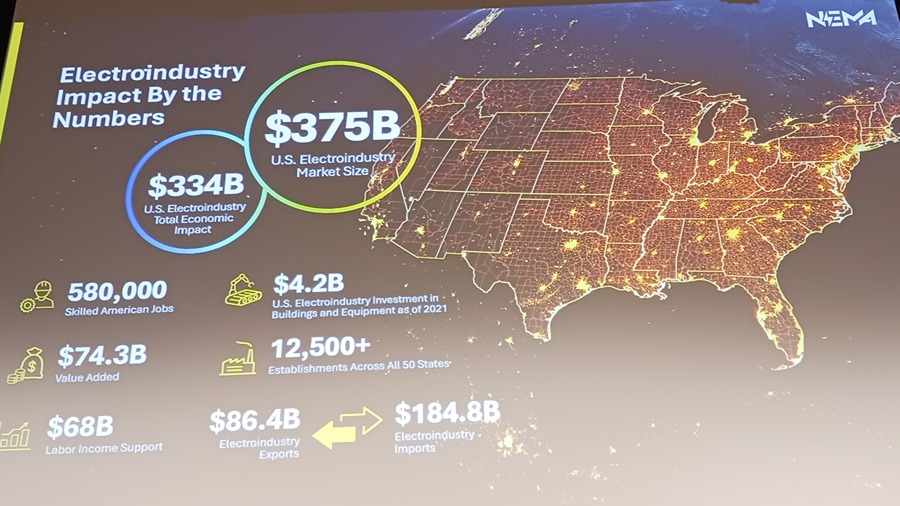
Workforce Development
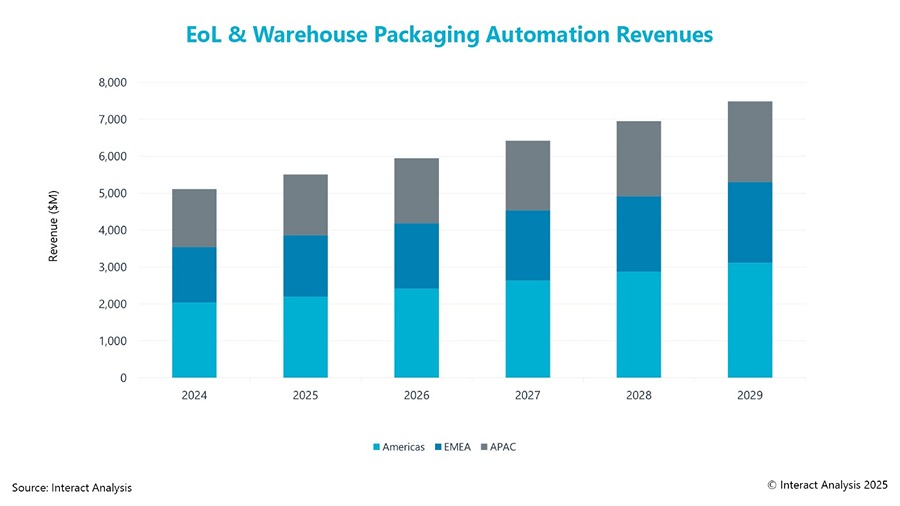
Automation
The Downtime
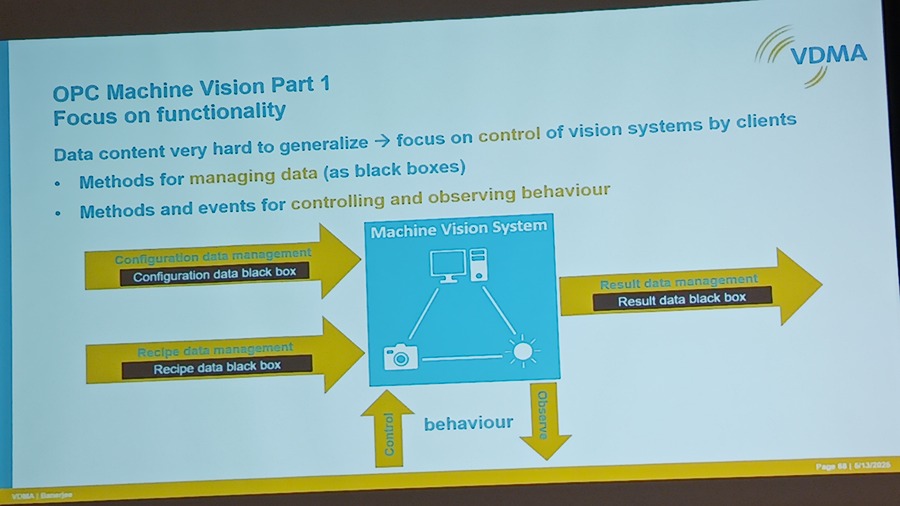
Vision and Discrete Sensors