To coffee drinkers and auto mechanics, “filtering” extracts unwanted contaminants from a stream of valuable material. Control engineers, on the other hand, use numerical filters to extract streams of valuable data from measurement noise and other extraneous information (see the “Filtering the feedback” graphic).
|
To coffee drinkers and auto mechanics, “filtering” extracts unwanted contaminants from a stream of valuable material. Control engineers, on the other hand, use numerical filters to extract streams of valuable data from measurement noise and other extraneous information (see the “Filtering the feedback” graphic).
The “Running average” sidebar shows how the most basic numerical filter—a running or moving average —can extract the average value from a sequence of recent process variable measurements. Averaging is an especially effective method for determining the true value of a process variable when the measuring device is prone to unpredictable fluctuations commonly described as noise. Measurement noise affects all industrial instruments to one degree or another. Variations in ambient conditions (especially temperature) or interference from nearby electrical sources can cause an unfiltered instrument to report a skewed reading. Sometimes the measurement technology itself is not entirely accurate, causing unfiltered measurements to deviate from the process variable’s true value.
If deviations are brief, random, and equally distributed between positive and negative values, the noise will contribute no net effect to the average of recent measurements, so the readings reported by a filtered instrument will be accurate. Even if the noise is not strictly random and has a non-zero average or mean , an averaging filter can compensate by detecting the mean and subtracting it from the instrument’s readings.
Alternative methods
The ability to extract accurate measurements from noisy data makes numerical filtering de rigueur for virtually all industrial instruments. However, most use more sophisticated and effective filtering techniques than a simple running average.
For example, a weighted average discounts older measurements in favor of newer ones when computing the instrument’s reading, as in the “Weighted average” sidebar. Unlike a running average, this technique recognizes that the process variable changes over time so that recent measurements are likely a more accurate depiction of the current process variable than older measurements.
The forgetting factor technique is similar, though more computationally efficient. It too gives greater weight to more recent measurements but requires fewer calculations and less memory than either a moving or weighted average. See the “Forgetting factor” sidebar.
 |
| A numerical filter inserted in the feedback path of a control loop can reduce the noise that often corrupts the process variable measurements. Less noise in the feedback path typically leads to smoother control efforts. |
Filtering without a computer
The forgetting factor technique also has the advantage of easy implementation with simple mechanical or electrical devices, and does not require a computer.
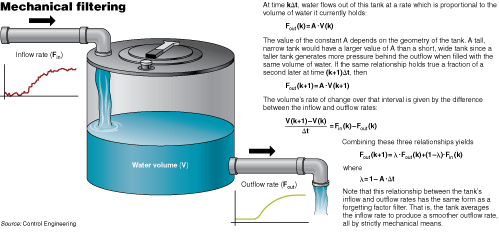
Consider, for example, the problem of extracting a smooth flow of water from an erratic source that is subject to random surges. A closed-loop flow controller could be installed with a valve and flow meter to counteract fluctuations in the upstream flow rate, but the same effect could be achieved by simply passing the stream through a tank as shown in the “Mechanical filtering” graphic.
If the tank is large enough, the water level inside will eventually stabilize at a point where the outflow rate equals the average inflow rate. Fluctuations in the erratic inflow will be averaged out over time by the tank’s storage capacity. The mathematical relationship between the two flow rates (as shown in the graphic) will have exactly the same form as a forgetting factor filter, though λ is typically described as a time constant when such a filter is implemented by physical, rather than strictly numerical means.
Challenges
This example also demonstrates one of the principal drawbacks of using a filter to eliminate noise from a data stream (or in this case, a literal stream). Filtering slows down the measuring process.
Imagine that the supply has been shut off somewhere upstream. Until the tank drains the outflow continues and does not indicate that the inflow rate has dropped to zero. A large tank would take longer to drain, prolonging the outflow and inflow disparity. In other words, the tank would take a long time to “forget” the old inflow rate, so its forgetting factor/time constant would be particularly large. A large tank’s storage capacity can average inflow rate fluctuations over a longer period of time, minimizing the effect of any individual surge. Better averaging is also characteristic of a numerical filter with a large time constant.
Process designers applying this mechanical filtering technique would size the tank to fit their objectives. A larger tank with a larger time constant would produce better averaging, but a smaller tank with a smaller time constant would be more responsive.
The same design trade-offs affect strictly numerical filters as well, especially those in feedback control loops. A filter with a long time constant does a better job of eliminating measurement noise, but it averages actual changes in the process variable over time, so it takes longer for the controller to see the effects of its previous control efforts. If the controller is impatient, it could apply more correction than necessary, much as when the process itself is slow to respond because of excessive deadtime. (See “Dealing with Deadtime”, Control Engineering , July 2005.)
 |
Sophisticated filtering
These simple averages are only the most basic filtering techniques. Nth order filters have N forgetting factors or time constants for improved performance. High pass filters preserve the high frequency components of the data stream rather than the low frequency components. Band pass filters discard both the highest and lowest frequency components and leave the mid-frequency components more or less in tact. Band stop filters perform the converse function.
All these techniques have advantages and disadvantages, and all involve complex mathematical analysis. Fortunately, signal theory —the study of data streams and methods for filtering them—is one of the most mature facets of control engineering since these techniques were developed in electrical engineering and telecommunications long before Ziegler and Nichols tuned their first loop.
As a result, there is a host of design tools and software packages to assist developing a filter with desired characteristics. These tools can also be used to design entire control loops since a feedback controller is essentially a filter that acts on the measured error between the process variable and the setpoint to produce a sequence of control efforts with desired characteristics.
| Author Information |
| Vance VanDoren is consulting editor to Control Engineering . Reach him at [email protected] . |
Running average
The output of a running average filter at time (k+1)Δt is the average of the last n+1 inputs sampled at intervals of Δt seconds:
| F out (k+1) = | F in (k) + F in (k-1) + in (k-n)
n + 1 |
For the purposes of a instrumenting a feedback control loop, the filter’s inputs would be the n+1 most recent process variable measurements, and the output would be the filtered reading reported by the instrument. Note that the output can also be computed recursively according to
| F out (k+1) =F out (k) + | F in (k) – F in (k-n-1)
n + 1 |
This alternative approach involves fewer calculations but still requires storing all of the last n+1 inputs somewhere in the filter’s memory so that the value of F in (k-n-1) can be recalled when needed.
Weighted average
The output of a weighted average filter depends more heavily on the values of the more recent inputs:
| F out (k+1) = | F in (k) + w in (k-1) + in (k-n)
1 + w + |
The weighting factor w can be assigned a value between 0 and 1 in order to quantify the relative importance of older vs. newer inputs. If w =0, the older inputs are discounted entirely. If w =1, all inputs are given equal weight just like a running average. And like a running average, the output of a weighted average filter can be computed more efficiently with a recursive formula:
| F out (k+1) = w out (k) + | F in (k) – wn in (k-n-1)
1 + w + |
Forgetting factor
A filter equipped with a forgetting factorλ between 0 and 1 gives more weight to more recent inputs much like a weighted average filter:
F out (k+1)=(1-λ) · F in (k) +λ · (1 – λ) · F in (k-1) +λ in (k-2)+
However, this technique incorporates all past inputs into the filter’s output, not just the last n+1 . The input measurement that is mΔt seconds old is discounted by a factor ofλ 0 , the older inputs are forgotten immediately. Ifλ is close to 1, the older inputs are forgotten relatively slowly. Note that the recursive version of the forgetting factor formula is the most computationally efficient of all averaging filters:
F out (k+1)=λ · F out (k) + (1-λ) · F in (k)
Only the current input and the current output need be stored at time kΔt for use at time (k+1)Δt .
FEEDBACK
Thanks for another thought-provoking tutorial article. Given that the first-order lag filter equations derive directly from substituting of Tustin”s bilinear transformation into the familiar "1/(s+a)" single-pole lowpass filter, I am a little surprised that you didn”t make a stronger connection to general linear filtering. A second order lowpass filter is sometimes a useful alternative. Also, you did not mention the common mathematical terminology "exponential weighting," which derives from the study of convolution filters as discussed in recent past issues of Control Engineering.
It would have been helpful if the key illustration "Filtering the Feedback" had shown plausible filtered signals, the way they would look given your discussion in the "Challenges" section. The filtering will reduce noise, but the bandwidth reduction will have side effects of making the transient shape "rounded at the corners." I”ll estimate that the high-frequency noise reduction factor as shown is about 6 or 7. For the running average filter: guided by the "Central Limit Theorem," the running average block length must be around 40 terms to produce this much high-frequency reduction. A 40-term average gives you a statistical estimate typical of the center of the data block, 20 samples in the past. The illustration shows the high frequency attenuation, but no 20-sample group delay and no transient shape rounding.
The filtering hazards have an important relationship to frequency response, which was not mentioned. A 40-term average has a roughly proportional-1/F amplitude rolloff envelope, with cutoff frequency at about 1/20 of the Nyquist frequency. If you were doing PID control, the "D" term has an proportional-F amplitude gain… which means that above 1/20 of the Nyquist frequency the filtering pretty much cancels out the benefits of the "D" term.
A 20-sample time delay introduces a 180 degree phase shift all by itself for a frequency at 1/20 of the Nyquist frequency of the sampling. Since the Nyquist stability criterion depends on the loop gain where the phase shift is 180 degrees, and the plant gain tends to be much higher at lower frequencies, that leaves less gain for the feedback loop to use. With lower gain, the result is poorer regulation performance. You mentioned the Ziegler-Nichols tuning rule: it is instructive to compare how that rule”s recommendations change when you go from a 1-sample to a 20-sample time delay in the plant model! This is a very real engineering tradeoff: short term noise variance vs. longer-term regulation variance.
None of this contradicts anything you said… it just makes a stronger statement about why filtering in feedback loops is very tricky business and should be done with greatest care. It is not the direct effects, rather the side effects of the filtering that cause the problems. Instead of a filter the delivers a good statistical estimate of what went on 20 samples in the past, what you really want is a filter that produces good (if imperfect) estimates of what is going on "right now" with most of the noise removed. If you had that, the filtering game would be a lot different. Which opens a whole new can of filtering theory worms. This theory wasn”t fully developed until decades after Ziegler and Nichols tuned their first PID loop: optimal Wiener filtering, observer theory, and Kalman filtering. Do you dare to go there???
Larry Trammell – 2008-23-10 14:13:00 CDT
Feedback



