Subject matter experts best positioned to judiciously transform process data for analysis
What’s the barrier to getting insights from data?
Process plant time-series data analysis can’t proceed effectively until the data is cleansed by subject matter experts (SMEs). Simply put, raw data is not ready for analysis and the realization of benefits. Some organizations report over 70% of the time dedicated to analytics is just for data cleansing to take the data from raw to ready.
This data is typically stored in the cloud in a data lake, or on premises in a process historian. Incidentally, for both options costs are dropping rapidly. At the same time, lower prices for sensors are creating more data than ever, with wired or wireless communication offerings widely available to move data from sensors to storage.
This creates an immense opportunity for plant personnel to leverage data created by their processes and assets, but also leaves a gap, commonly referred to as being data rich and information poor.
SMEs with first principles knowledge are required to cleanse, model, and contextualize data prior to undertaking efforts for business analysis, data science, and process-related analytics. Further, data scientists can’t run their algorithms until data is “ready.” For all their expertise in algorithms, data scientists don’t have the plant, asset, or process expertise to know what they are looking for in the data.
But SMEs aren’t data janitors, so the monotonous and time-consuming tasks of accessing, cleansing, and contextualizing data for analytics must be addressed – driving the search for better solutions.
Advanced applications required
While the goal of analytics is obtaining insights, this must be done in the context of the organization’s data security requirements. For this reason, there are rules and processes expressed in company data governance protocols to only allow data access by authorized employees. Therefore, any advanced analytics application used for data manipulation must adhere to these rules and processes.
Further, when gathering data from manufacturing operations, it’s essential the process data remains stored in its native form without any cleansing or summarization. This is because the slightest incorrect assumption regarding how to change the data before executing analytics could negatively impact or degrade the opportunity for future insights. Therefore, transforming data from raw to ready should not occur prior to data storage, and it is a task best left for SMEs. These experts have been using spreadsheets for an entire generation to cleanse data, but this general-purpose tool is not well suited to this task.
Furthermore, traditional business intelligence applications are great for relational data sets, but they don’t accommodate the dynamic nature of time-series data. This means many try to use spreadsheets for data cleansing and contextualization, a slow and manual process.
For example, fundamental issues of time-series data like time zones, daylight savings time, and interpolation types and logic must be addressed by the user in spreadsheet formulas. And what one person does on their desktop may not be discoverable by their colleagues, so work must be repeated time and again. The result isn’t just hours in spreadsheet hell for SMEs, it’s weeks or months. These types of issues drive companies to look for a better solution in the form of advanced analytics applications.
Contextualizing for analysis
Contextualization comes into play when SMEs prepare the data for analytics through integration and alignment of data from multiple sources. This is sometimes also referred to as data harmonization, data blending, data fusion, or data augmentation. Essentially, SMEs are matching up unlike data types to inform a full-picture model of the asset or process by combining things like the sensor data, what the asset or process is doing at the time, and which parts of the data are important to operations.
This is an increasing challenge as process manufacturing companies generate ever more data – 1TB/day (terabyte per day) for the average plant and perhaps 40TB/day for a corporation with multiple plants (see Figure 1) – to record flow, temperature, pressure, level and other parameters of interest.
Let’s look at a specific example of the challenges arising when working with time-series data. A data set from a sensor reporting data every second for a year results in a total of 3.1 million data points for the year, each in the form of timestamp:value.
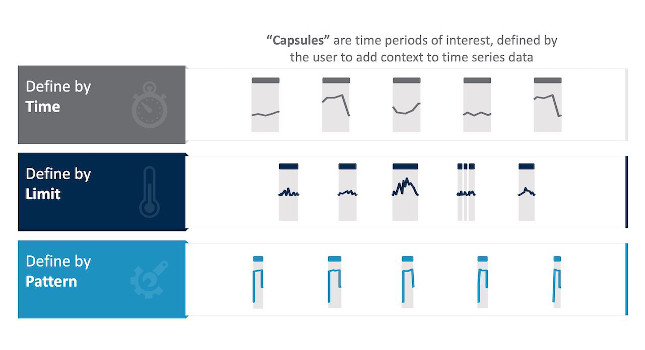
It’s not feasible in most cases to examine all this data, nor is it necessary. Instead, SMEs would typically only want to look at specific periods of interest within this year-long signal. Here are a few examples of what they may be interested in, with data points examined for analytics only when the following conditions are true, and otherwise ignored (see Figure 2):
- Time period: by day, by shift, by Wednesdays, by weekdays vs. weekends, or more
- Asset state: on, off, warmup, shutdown, or more
- A calculation: time periods when the 2nd derivative of moving average is negative
- Erroneous data samples due to lost signals, flyers, dropouts, or other issues – each requiring cleansing to improve analytics accuracy.
What is apparent from this example is that even with just a year of recorded data from only one signal, there are virtually unlimited ways to parse the data for analysis. Also apparent is the need for SMEs to wisely choose these time periods of interest when transforming data to a ready-for-analytics state.
Some chemical production environments can have 20,000 to 70,000 signals (or sensors), oil refineries can have 100,000 plus, and enterprise sensor data signals can reach into the millions. The amount of data can be overwhelming but refining and reducing it can lead to accelerated insights (see Figure 3).
Another hurdle to consider when making time-series data ready for analysis is the interpolation and calculus often required for analyzing data, which is something that can be missed by IT data consolidation and aggregation methods. Manufacturing-specific solutions are required because they provide the ability to align signals with different sample rates, from different data sources, in different time zones. These and other data cleansing tasks are unquestionably necessary before defining relevant time periods of interest.
The contextualization step
A way to expand on operational data gathered from specified time periods of interest is to contextualize it with data from other sources to improve the impact on overall business outcomes. When combining various unlike data sources, common questions can include:
- What is energy consumption when making Product Type 1 versus Product Type 2?
- What is the impact of temperature on product quality?
- Does power consumption change as batch completion time varies?
Some examples of common data sources include laboratory information systems, manufacturing execution systems, enterprise resource planning systems, external raw material pricing systems, utility pricing, and more.
Here is an example of data contextualization required to combine and work with data from multiple sources. The result is a table (Figure 4), which is easy to understand and manipulate. It is also accessible to SMEs, along with analysts using business intelligence applications such as Microsoft Power BI, Tableau or Spotfire.
Insightful futures for time-series data
Advanced analytics applications are easy to use with time-series data, empowering SMEs to quickly cleanse and contextualize data, in stark contrast to spreadsheet-based labor-intensive analytical efforts. With these types of applications, data is accessed from silos as required, and is never copied or duplicated. It is then used for diagnostic, predictive and descriptive analytics.
Advanced analytics applications should enable collaboration among colleagues with published reports and dashboards for insights across the organization, without the need to rifle through hundreds of thousands of rows in spreadsheets. With advanced analytics applications, it’s possible to quickly get the insights organizations need to realize the full value of time-series data, making this data as easy to analyze as it is to collect and store.
There is tremendous focus on digital transformation making its way onto the radar of industrial organizations. Combined with the pressure of integrating information technologies and operations technology assets to develop a holistic view across business and data sets, this attention makes it more relevant than ever for process manufacturers to understand the importance of proper data cleansing and contextualization of their time-series data. This will lead them to insights as vast as their raw data sets, closing a gap that has existed for far too long.



