Artificial intelligence (AI) can have an enormous impact in industrial manufacturing, but the trust and belief in the system that it is making the right decisions is critical.
Learning Objectives
- Learn about the role artificial intelligence (AI) plays in industrial manufacturing operations.
- Understand AI’s limits as well as its potential and the human role in shaping and guiding its development.
- Understand some of the ethical and moral changes to AI as well as how critical people’s trust in the system is.
Artificial intelligence (AI) insights
- AI’s role is growing in manufacturing, but its ability to help manufacturers improve operations and grow the bottom line is tempered by the workers’ ability to trust AI is making the right decisions.
- Trust is a major component to AI and some of the key aspects include explainability, competence, operational transparency, predictability and ethics.
Artificial intelligence (AI) is making decisions everywhere. In the factory and other industrial applications, artificial intelligence is scanning for product defects. It’s guiding robots across a shop floor. AI can tell you when your production line is about to go down – and how to fix the problem before it happens. AI will help your engineers how to optimize production or cutback on waste. AI systems can help keep workers safe by identifying when they step into a dangerous area. The challenge is whether people can trust these decisions.
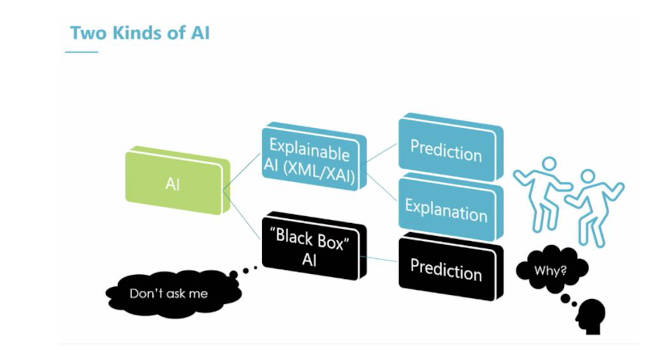
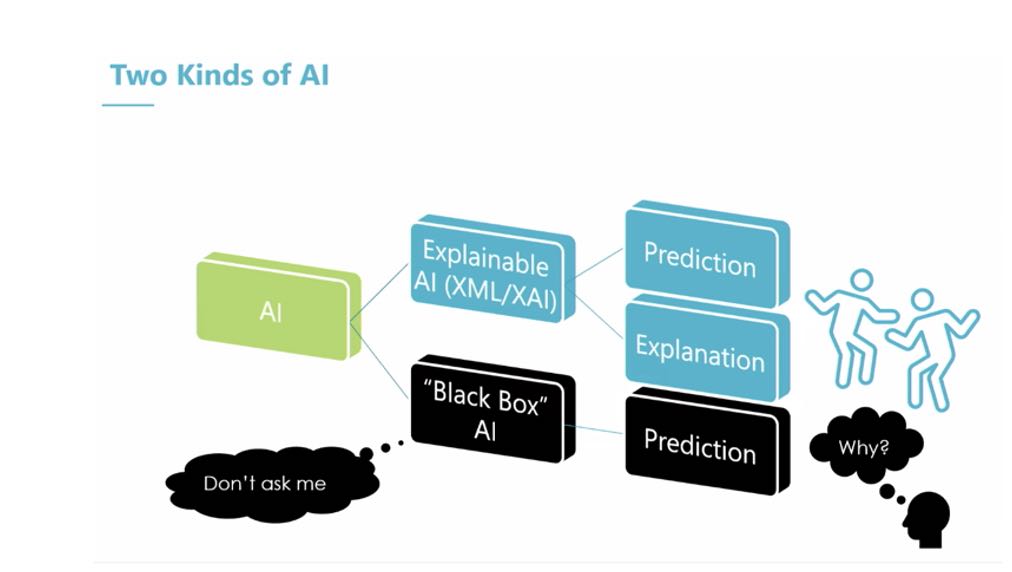
Decisions made by complex deep learning neural networks are often rendered without explanation. Since these systems are basically programming themselves, their decision making lack explainability. This has been called Black Box AI. Ongoing research has been aimed at building more transparency into AI’s decisions.
For those deploying AI right now, how do we know if we can believe what AI is saying? It’s one thing to deal with the repercussions of a poor buying recommendation or an incorrectly declined credit purchase. But what happens when critical operations – and especially our safety – rely on AI?
Trust is a firm belief in the reliability, truth, ability and/or strength of someone or something. For people to believe in AI, they need more than a black box explanation that “AI just works.” It needs to go beyond that and users need to trust AI in ways such as:
-
Explainability: Users need to know why AI systems make the decisions they do.
-
Competence: Users have to understand the limits of AI. In addition, AI systems also need to be aware of and accommodate their own limitations.
-
Operational transparency: Users must see how AI systems are operating in real-time and know why they behave the way they do.
-
Predictability: Users have to be able to anticipate how AI systems might respond in particular situations.
-
Ethics: AI systems must avoid ethical issues that can break trust if not addressed with care.
The importance of trust
Irene Petrick, the former senior director of industrial innovation at Intel, said when it comes to trust, “We asked tech companies what was most important to them. About a third of their comments revolved around trust (Figure 1), such as did the AI use the right data in the right way. AI should drive more and better action quickly, in a way that anticipates other issues. If a user doesn’t trust the AI, this doesn’t drive action.”
Anatoli Gorchet, CTO at Neurala, describes trust issues that can arise from the limitations of generalization in his presentation at the 2022 AI and Smart Automation Conference. For example, a common AI blind spot is environmental variance. If training model data is captured just in the morning, model accuracy will plummet in the afternoon or evening because the angle of the sun has changed. This creates a trust issue with users because a person would not make such a mistake.
Note that environmental variances can be extremely subtle. Consider a successful AI deployed to a new line that severely drops in accuracy. Even though engineers thought the line was identical to the original line, it wasn’t: The new operator was six inches taller than the original operator and blocked more background light, changing the environmental conditions sufficiently to bring the neural network down.
Gorchet points out that trust takes a lot of time to develop and but just a single event to break. The challenge is, how do we teach people to trust systems that can fail like this?

Producing data that can be trusted
AI models are built on data. Thus, it makes sense that if users are to trust an AI, they must be able to trust the data used to build it. Dominik Boesl, CTO at Micropsi Industries, shared a number of different ways data can impact trust.
Trust in data starts with careful capture of that data. “In one case, a pen was on the table during training. The AI thought the pen was a point of reference,” Boesl said. “It takes just one image without a pen to show it isn’t essential.”
Developers also need to consider sampling bias, as it can affect the accuracy of the system. A common example of sampling bias are environmental conditions such as lighting. “AI is not always the same. There are different types and technologies. And what a person looks for doesn’t necessarily match what an AI is looking for. Back in 1995, NATO used recognition software to differentiate friendly from enemy tanks. It did not perform well. After months of troubleshooting, they uncovered that the training data had been taken from clean brochure pictures with bright lighting, not of tanks covered in mud or under low lighting. The AI was focused on clear vs dirty.”
“Variance is essential in data,” Boesl said. “Consider how Tesla demo drivers must have a 95% driving record. The car is being trained to expect a predictable driver. But not every driver will be predictable.” Adding variance removes blind spots by showing a wider sample of what is acceptable.
“With enough variance, there is no need to show undesired states, no need to say good or bad. We make sure to use a variety of white and colorful backgrounds to teach the AI not to count on the background. To get light independence, we use a video projector to light the system while training. As the light is constantly changing, this teaches the AI that light is not a relevant feature. And have a trained operator teach the AI rather than an engineer. The operator is the expert and the person who will be working with the AI.”
Dr. Nurali Virani, senior scientist – machine learning at GE Research and head of GE’s Humble AI Initiative, said, “At a fundamental level, if the model is too confident in its prediction in rare and challenging situations with limited/no training data, then it can be an extrapolation error. It helps to understand the user’s perspective. Many technicians and end users have years and even decades of experience. Rightly so, they can ask, ‘How does the AI know better than me in such challenging situations?’”
“There is also the matter of human error. If some data is labelled incorrectly, the AI will be unreliable for similar instances. If AI relies on that data for confident predictions, then it can lead to breach of trust. However, if AI can know, which labels are likely to be erroneous and be robust to some label errors, then it can ask for feedback to maintain trust.”
Gorchet believes that how an AI system is developed impacts trust. Consider that when developers change hardware, they might have to change the Cuda version, as well. Some of a user’s models might not be supported because Tensorflow is not supported with the new version. This might lead a user to question what else might not be working. It is critical to abstract these kind of development issues from users.
AI and competence
Another foundation of trust in AI is awareness of its limitations. Virani said, “We have coined the term Humble AI to refer to an AI that is aware of its own competence, can ask for help, and grow its competence over time. When it sees it is beyond the region of its competence, it passes the decision to the operator or falls back to other safe modes of operation. Eventually, this new data can be worked into the models to raise the competence level of the AI.
“This is an important idea. An AI does not need to work everywhere at the outset. It can be used just where it has enough data to be helpful – and trusted. For example, the AI might not know how to diagnose a new fault in an industrial system. It says, ‘I don’t know, you’re the expert, please help me.’ However, the AI might know enough to say what the situation isn’t. ‘It’s not fault A, but it could be fault B or fault C.’”
When developers accept competence as a factor, this can build trust. Virani said, “Without competence, an AI will make decision even when it doesn’t know the answer.”
Rather than risk giving the wrong recommendation and destroying the user’s trust, the AI can narrow down the options. It is still helpful. It is still correct. And so it continues to build trust and reduce the workload in areas where it has competence.
“Generalized AIs have the challenge of working under all conditions,” Virani said. “But if all of an AI’s data is from during the day, it will likely have trouble at night. You can’t cover every possibility in the beginning. So it’s important for a model to be able to say, ‘I can’t be trusted here.’ It needs to have self-awareness of its limitations. Start with support in relevant regions, not full autonomy. Build trust in stages.”
This suggests an approach to deploying AI by decomposing complex problems into smaller parts. At first, the overall accuracy may be low. For example, Virani’s work with the machine learning (ML) team at GE has sown in [1] that an AI model for maintenance record tagging might have poor overall performance (80%) but in a region of competence, where the model thinks it can be trusted, it can provide 97% accuracy.
Thus, more than 50% of document tagging cases could be automated and other cases required some human help to tag the ambiguous or anomalous instances. These new tags from humans can be used for updating the model. Participating in the training of a trustworthy AI and seeing its development can be a powerful foundation for it to become a trusted AI.
Boesl said, “We differentiate tasks for every customer. Solving a dedicated problem is easier and faster than solving a general problem. For example, we teach a robot how to plug in a specific cable, not cables in general. We also train to a certain facility to capture its environmental conditions. The AI can transfer skills to a second cable or second facility through a recalibration process that captures all the relevant differences between the scenarios. Recalibration takes some work but much less than starting from scratch or creating a fully generalized approach. With this approach, smart robots can be trained in hours or days compared to weeks to program robots line by line. In addition, robots can be retrained or the production line changed with less investment.”
Gorchet suggests that rather than train for all possible scenarios, train for the ones already happening. This could be cheaper than creating a generalized model even if the team has to make multiple specific training.
It helps to remember AI is an evolving field. If an AI is not delivering the results needed, it’s quite possible this is not a problem AI is able to solve today. Better to acknowledge this than claim the AI can do something it can’t. Because when it has its first failure, trust is broken and is difficult to regain.
Boesl said users should have the ability to stop or pause smart equipment. “People have to have the perception that they are in control, that a machine can be shut down if something is wrong. Humans control machines, not machines controlling humans. A lot of trust can be lost when users feel like they are being controlled. At the same time, users need to have the limitations of AI explained. For example, people walking on a factory floor must be aware that a mobile robot has right of way or that if they step over black and yellow tape on the floor they could get seriously hurt.”
Explainability builds trust in AI
Explainability is one of the primary tools for building trust. In short, it’s the idea that, if a user understands how an AI makes decisions, they will be more open to trusting its recommendations. An added benefit of explainability is that it makes it easier to verify that an AI is performing as expected. This can accelerate development for engineers, as well as build trust with users. Explainability is also important up the line. For example, a manager might ask, ‘Why is this robot so slow?’ While the robot could go faster go, it is going this speed to protect workers.
Gorchet describes the “black box” problem with AI (Figure 2). Trying to explain how a neural network works to a user is not explainability.
Petrick said, “Explainability starts with, ‘Why the heck am I doing this?’ If the why isn’t explained, this creates a foundation for unease and distrust. To get buy-in from workers, to encourage their engagement, they need to understand the challenges a company is facing, how AI can help, and their own essential role in the overall solution. Only then can you discuss what’s happening inside the black box. Next, we advocate explaining how the AI works in plain language. Here’s how the AI breaks the task down, how it assesses it, and how it makes a recommendation. Just because an AI solution can be 100% automated, it can help to introduce this automation in stages. Once the user receives a recommendation that is correct, they tend to be more comfortable in releasing that decision to the AI as a partner.”
Gorchet described how to use images of good products for training so no labeling is required. When the AI thinks it detects a defect, it draws a segmentation mask where it thinks the defect is. You can see why the system made the decision it did. If the mask shows something that is not a defect, the system learned something that is wrong and can correct it.
Virani tied competence and explainability together. “The overall accuracy of a particular AI on some validation dataset is not as important as knowing the expected accuracy of the current recommendation. There also needs to be a level of explainability for why the AI is confident or not confident in a particular instance. For example, creating a wrapper using the training data with its labels enables the AI to refer to the relevant data that it used to make a decision. We have explored this exemplar-based explainability for AI models to provide justification for their predictions in our projects. [2]. Of course, this is not always useful. If the decision was made at a pixel level on an image, a user may not understand what they are looking at when the AI shows them examples of pixels from training data.”
That is part of the trouble with explainability. AI can be complex, and the tools available abstract this complexity for developers. For example, with no-code generated AI systems, developers tell the AI what they want to do, and the AI generates its own program. However, this abstraction just makes the black box much more opaque. All a developer can do to check the AI is to put data in and verify the result is correct. In some cases, there may be little if any explainability possible.
Petrick said, “If the developer does not understand or cannot explain how the black box works, how can the user be expected to understand? And if it takes too work to understand and assess the reliability of the AI, the user may determine that it is more efficient not to work with the AI.”
One way to address the challenges of explainability is two-way communication. Petrick said, “AI engineers are learning the hard way that they do not understand the nuances of the factory floor. An AI ‘solution’ trained on the factory floor should be simple to transfer to another factory laid out in the same way. But this is often not the case. For example, environmental factors such as lighting, dust, water spray, camera angle, and a plethora of others make each situation different. Effective explainability includes a feedback channel where the users who work with an AI can provide insight as to how the AI does not meet their needs.”
The role of ethics in AI
Part of trust includes feeling like a user’s best interests are being kept in mind. And when users feel afraid or that they are not essential, trust erodes.
Petrick said, “Robots free up people to do the tasks that only people can do. Robots help maximize a person’s potential to deliver value. However, when the AI is considered more reliable than the user, this can put the user and AI in conflict. The user needs to be able to say, ‘I make the decisions. The AI helps me and does what I don’t want to do.’ Currently, ethics with AI technology are only being considered by 20% of manufacturers interviewey. Many people think ethics are all about data bias. For example, the AI in an oxygen pulse monitor might be less affective on darker skin because engineering didn’t realize the sensor doesn’t read through as well. One of the challenges with data bias is that the bias is not intentional. It’s often a blind spot, a possibility no one considered. But that’s not the only ethical issues to take into account.”
Privacy can be essential to trust as well as well. Operators want to know how data about them is being used. Petrick said, “We tend to measure what is easiest to measure.”
Office workers don’t want their productivity to be assessed by how many times they click a mouse as this doesn’t accurately reflect the job they do. Operators feel the same way about arbitrary assessments of their productivity that can be used against them. Consider a user who gets more troublesome cases because of their expertise; they produce less because of the higher difficulty. Systems need to be aware of a person during operation, but some believe the person needs to be scrubbed out of the data. Petrick said, “The industry is just at the tip of iceberg regarding privacy.”
Virani said, “There’s also equity to take into account. Consider an AI that wants to recommend the best technician to fix something. If the data set is not diverse enough, the AI will make this person only do tasks that they have previously done well. Not only could this become a burden to the technician, from an ethical standpoint, the technician will not have an opportunity to gain new experience and grow within the company. Thus, when personnel is in the mix, make sure their needs are met as well.”
“This approach could also create a single point of failure since only a limited subset of technicians get the experience of handling this issue. You might have more options in your talent pool, but they never get explored, so no one else gets to learn how to address this issue.”
When to comes to accountability, Petrick said, “What happens when the AI fails, and it looks like the user is responsible? Explainability needs to extend to be able to explain not just what is going to happen but what actually happened. If users don’t believe they have a way to protect themselves, they will have less trust in the system. This is not an unfounded consideration. Engineers are creating AI for environments they have never worked in.”
Consider the ethical use of data. Boesl said, “With regulations like the GDPR, there is much debate about who owns data. There are also ethical issues that can arise. For example, can an AI company working with data collected at a customer’s facility use that data to improve operations for the customer’s competitors? I think it is important that this should not be possible. Issues like these can destroy trust if not addressed carefully.”
Ethical issues are only going to become more commonplace – and complex. Today, cameras are pointed at the production line. But when those cameras turn around and include the user, there are a wide range of ethical issues, varying from country to country, that will have to be taken into consideration.
As we’ve seen, trust is essential to getting the most out of AI technology. With explainability, trust can be built faster and with user buy-in. And when ethical issues are considered as important, this is the best defense to protecting trust from being broken.
Nick Cravotta is a contributing editor for the Association for Advancing Automation (A3), a CFE Media and Technology content partner. This originally appeared on A3’s website. Edited by Chris Vavra, web content manager, Control Engineering, CFE Media and Technology, [email protected].
MORE ANSWERS
Keywords: artificial intelligence, AI, machine learning, ethics
ONLINE
See additional AI and machine learning stories at https://www.controleng.com/ai-machine-learning/
CONSIDER THIS
How much is AI growing at your company and what does it mean in the short- and long-term?
References (from Nurali at GE)
[1] Iyer, N., Virani, N., Yang, Z. and Saxena, A., 2022, October. Mixed Initiative Approach for Reliable Tagging of Maintenance Records with Machine Learning. In Annual Conference of the PHM Society (Vol. 14, No. 1).
[2] Virani, N., Iyer, N. and Yang, Z., 2020, April. Justification-based reliability in machine learning. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 04, pp. 6078-6085).