Centralized data architectures are adapting to new opportunities for data collection and analytics.
The starting point of a discussion with data and advanced analytics needs to begin with Moore’s Law. In 1965, Gordon Moore, a co-founder at Intel, noticed the number of transistors on a chip doubled every year while the price was cut in half. He predicted this trend would continue. And while the number of transistors per chip has slowed recently, researchers find the basic point is still true.
Data storage prices have plummeted, prices have crashed, and computers are a fraction of the size they used to be. And yes, what can be computed on the same-sized and priced chip has increased many times over.
We read about the results of this market transition every day: the data explosion; pervasive sensing and connectivity; the Internet of Things (IoT) with 50 billion endpoints; and how today’s smartphones are more capable in computing, storage and input/output (I/O) than not only early mainframes, but even Deep Blue (1997/IBM). This even applies to companies such as ExxonMobil, which made a $2 billion investment in Lockheed Martin to drive open systems architecture for process automation. For some companies, the price advantages of Moore’s Law have been too long in coming to manufacturing’s front lines.
The result of this ubiquitous and inexpensive computing is process manufacturers have an opportunity to re-imagine their data analytics strategies by implementing options that used to be too expensive to consider. Data used to be centralized for analytics because it was expensive to collect, store, and analyze.
Ubiquitous and less expensive computing will continue. Regardless of whatever one calls it–Industrie 4.0, smart manufacturing, digital transformation–the question is what to do with the data being collected.
New words for new models
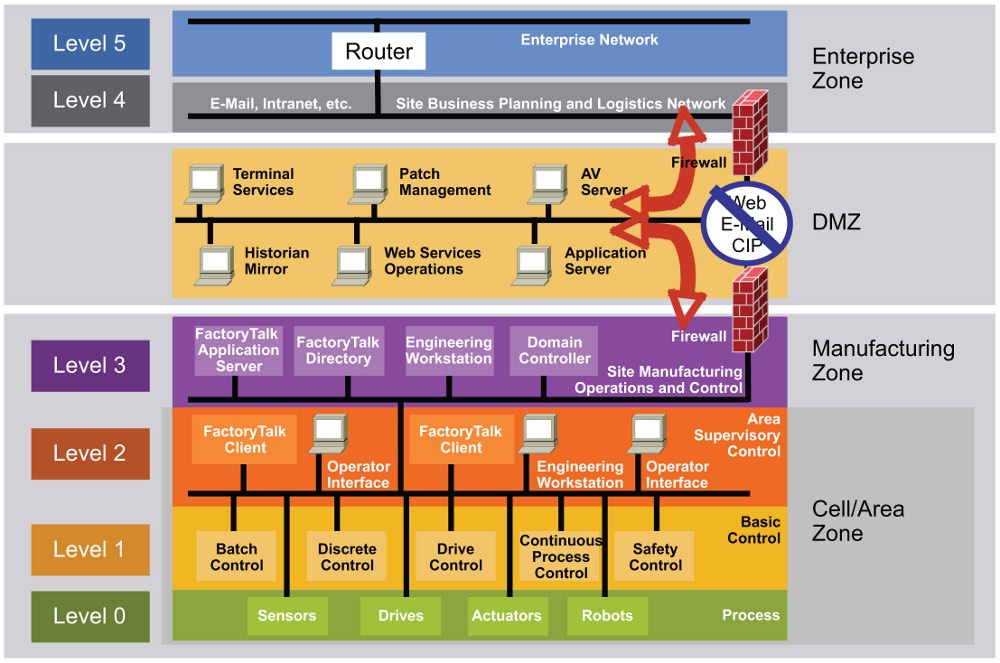
New economics and ubiquitous computing mean the Purdue-model centralized approach (Figure 1) is being adapted to new opportunities. The centralized model is the most common architecture in process plants worldwide and is familiar to users.
The Purdue model is being updated to take advantage of new technologies such as:
- Wireless systems integrating new sensors into existing control and monitoring deployments, either within a plant or at distance, to expand operational visibility.
- Edge computing, which is a broad term that includes local data storage, analytics, and actions.
- Cloud computing, which is simply renting computing, storage, and analytics from a vendor. This enables two key scenarios:
- First, a “direct to cloud” approach for data collection, storage, and analytics for sensor telemetry. This typically is referred to as an Industrial Internet of Things (IIoT) use case where data goes directly from end points to cloud storage.
- Second, for data already collected to be further aggregated for comparison across plants, by using an enterprise historian, or combined with other manufacturing and business data sets to enable broader analytics, often referred to as a data lake.
These approaches are not exclusive, and most companies will use more than one, if not all. For example, a plant could bring in data from newly deployed wireless sensors to augment existing plant analytics. This could be combined with data from suppliers, data from raw materials transportation such as temperature and humidity, and data from quality instruments for richer analytics and insights.
Further, options will expand as new solutions are announced. Into what category should one put the Amazon AWS and Microsoft Azure on-premise products, Amazon Outposts (Figure 2) and Azure Stack, which put their cloud software platforms on server hardware intended for local hosting in an end user’s IT department? Perhaps it’s public cloud, private cloud, and local cloud?
With a local cloud IoT scenario, data could be routed from new sensors directly into a company’s IT department server room to ensure strict data governance and to address security issues.
Some of these options will sound familiar to industry insiders. For example, vendors focused on edge computing will be hard pressed to explain how edge computing components differ from real-time units (RTUs). Similarly, cloud vendors pushing data lakes may be hard pressed to explain why their approach is substantially different than an enterprise historian that rolls up individual plant data.
It may be hard to separate out the vendor self-interest at play. Thus, it’s not a coincidence a fully decentralized and networked architecture of computing endpoints is being championed by the vendors who sell the required networking, CPUs, and operating systems.
Planning for ubiquity
Technology offerings clearly are evolving faster than the language used to explain them. Entire plants sometimes are considered the new edge. The other issue is the mismatch of innovation and time to implement. Products and marketing can be invented overnight. This is far faster than proof points and best practices from successful deployments.
Flexibility is being driven by lower costs and improved connectivity for where and how to deploy sensors, data collection, storage, and analytics. A comprehensive view of possible architectures and tradeoffs would be well beyond the scope of any article because by the time someone published a compendium a new crop of innovations and buzzwords would have sprung up. With these limitations in mind, here are four considerations about ubiquitous computing’s impact on plant architectures for data creation, collection, storage, and analytics.
1. What’s the starting point for a company?
For new sensor deployments, the collected data resides in the cloud even if the cloud is, in fact, hardware in a local data center. Of course, this is more appropriate for monitoring/visibility as the architecture will have to support communications disruptions in addition to meeting a host of data security requirements. Microsoft, Amazon, Google, and 100+ startups, including industrial-specific wireless companies, offer a full stack of “edge to insight” software. This approach offers rapid deployment and new cloud services revenue.
The alternative is brownfield plants where the center of gravity is, and will continue to be, on premise. Low latency, guaranteed networking, and local access to data are all key to this model, and these solutions are in place and working. A more likely scenario for brownfield plants is expansion of their data collection, either through local wireless solutions or through an adjacent cloud-based system where data is integrated with their plant systems. Where the data lands is flexible with this model, either on premise or in the cloud.
2. Does a company’s assets have neighbors?
In the edge computing model, the premise is any asset may be analyzed individually and diagnosed for predictive failure, optimized run time performance, etc. If the asset is operating independently, that makes sense. This, in effect, creates a smarter RTU model for high value assets.
However, if the asset has neighbors with a process unit or a line of machinery, which is often the case, it’s not so obvious where the data collection and analytics should occur. What can happen is adjacent assets end up fighting for optimization status. What’s needed is optimization of an entire process unit or manufacturing line.
The answer is aggregating the data from multiple assets at the line, unless it’s part of a larger unit. Careful planning for where data is collected, stored, and analyzed for optimization will be required except for in a truly stand-alone asset scenario.
Even then—given pricing, energy, and other inputs not available on the plant floor—it may mean the best result is where the system started, with a centralized data collection and analytics model.
3. Who owns the data?
With new computing architectures, the question is not only where should data be stored, but by whom. Asset vendors increasingly are offering remote monitoring services for the assets they sell.
This leads to several questions regarding data governance such as:
- Who owns the generated data?
- Does the data get copied twice (to the monitoring vendor and the plant owner)?
- How and to where does the asset data move (security, wireless, cloud), etc.?
- How are the insights brought back and integrated into the customer’s systems for operational improvements?
4. Who has the expertise?
Data inputs beyond the ones needed for real-time control and monitoring often are required to optimize asset, line, or plant performance. Examples are overtime costs for staff, rush order costs for spare parts, and commitments to customers.
These factors go into production optimization and are why plant engineers and experts have such encouraging employment prospects. Creating asset, plant, and performance context still is largely a function of employee experience and expertise. This will require advanced analytics offerings to access, visualize, and contextualize data to create insights (Figure 3).
This means that the employee’s access, whether it’s mobile or web-based, is critical regardless of decisions around edge or cloud data collection. Employees in the plant or headquarters should still centralize the data for analytics. This impacts data governance by dictating who gets to see what data as much as where the data is collected.
Some rules still apply
It is easier to start from the innovation and opportunities and work backwards to reality. In reality, innovation planning starts with the security, manageability, and other business priorities, and works backwards from there. Security dominates the discussion; especially as data collection and analytics are distributed. Furthermore, while edge or local devices sound more secure, the increasing sophistication of the systems increases their threat exposure. The more responsibility these components have for equipment operations, the more valuable they are as a potential target.
Reliability is the second issue after security. Data connectivity and bandwidth will be particularly important. Planning must include a discussion about what happens to the data when the network fails to the edge or the cloud.
New architecture considerations impacts how and where data is collected and analyzed. Information technology (IT), production, and business results related to return on investment (ROI) will have to be balanced.
New approaches for data
Pervasive computing propelled by lower prices for all aspects of computing is driving a new set of approaches for plant data architectures. In effect, this spreads out computing and analytics and prevents everything from being in one spot. Expecting Big Data and machine learning analytics to be applied to broader data sets is a key driver of this belief.
Innovation is outpacing customers’ adoption of it. Big Data was first, then Industrie 4.0 and the like. Now there are models for new computing innovation at every point in the process. Balancing what is now possible with the requirements for improving performance is the challenge with future innovations.
Michael Risse, chief marketing officer (CMO) and vice president, Seeq Corp. www.seeq.com Edited by Chris Vavra, production editor, Control Engineering, CFE Media, [email protected].
MORE ANSWERS
Keywords: Big Data, asset management, cybersecurity
Even with the advent of Smart Manufacturing and Industrie 4.0, process manufacturers need to know what to do with the data they’re collecting.
Process manufacturers need to plan for ubiquity and ensure their data is preserved and secure.
Computing innovations need to be balanced with improved performance.
Consider this
What changes will happen 10 or 20 years from now in manufacturing thanks to Big Data?



