How can it be considered "good engineering practice" to bypass your SIS during critical times with your process? See diagrams.
Although most facilities embrace ANSI/ISA 84.00.01-2004 (IEC 61511) and the safety life cycle (SLC) as the way to comply with regulatory requirements (e.g., OSHA 1910.119), there are specific instances when most operations deviate from the standard. These are during start-ups, shutdowns, and process transitions. Processes with adequately designed safety instrumented functions (SIF) that are validated to well-developed safety requirement specifications (SRS) are commonly—although momentarily—idled, and instead are practically replaced by a team of operators, managers, and specialized personnel. Bypassing, inhibiting, or masking is a common practice during these plant conditions. In these cases, the safety instrumented system (SIS) is temporarily replaced by humans in calculated and intensely watched conditions.
Why does this happen, and is it a good idea? What are the underlying assumptions that lead to this practice?
Permissive sequencing and ISA 84
There has been widespread adoption of functional safety concepts in process industries as a way to deal with process risks and to control safe operation. In particular, the S-84.00.01 – 2004 (IEC 61511 Mod.) standard has become recognized as a fundamental definition of how to implement concepts of a SLC and design of SISs for process industries. However, implementations have been constrained to steady-state protection functions and rarely applied to sequencing, either during start-up, shutdown, or dynamic transitions. Sequencing has almost always been left to a manual procedure and operator’s discretion.
Start-ups, shutdowns, and transitions have always been considered the most dangerous period for operations in process plants. If that is the case, what is the reasoning behind the suspension of safety systems during those periods, and is that reasoning justified? Moreover, do improvements in technology offer new ways to address some of the assumptions about permissive sequencing?
Armed with a full set of steady-state operating conditions and a list of process constraints, the SIS is designed to offer a layer of protection above the basic process control system (BPCS) and the operations team. While designed to protect the process at steady-state conditions, getting to the steady state typically involves a permissive sequence. Bypassing, inhibiting, or masking is a common practice during these plant conditions; in these cases the SIS is temporarily suspended.
In order to understand the reasons behind such a limiting practice on the use of safety systems, we must first understand what is involved in the implementation of a permissive sequence. Permissive sequences have three general characteristics:
- A time dependency that must be considered
- Changing variable thresholds or limits, and
- Interlocks that vary or may need to be inhibited or overridden.
Assumptions for suspension
There are five key assumptions that are used to explain and justify suspending SIFs during process transitions:
- Processes start-ups and transitions are infrequent and of short duration compared to steady-state operation. Therefore, SIFs can be suspended and start-up carried out manually with a written procedure under the supervision of a start-up manager.
- There is a lack of similarity between different processes. This makes prescriptive standards impossible and best practices difficult. Therefore, it seems acceptable to manage them manually under tailored conditions.
- There is a lack of similarity between a process-transition operation and steady-state operation. Safety systems are therefore designed to operate under steady-state conditions where the majority of the operating time occurs. SIS designers would have to create an entirely new and conflicting SIS to manage process transitions.
- The process transition operation is more affected by operational subjectivity and procedures than steady-state operation, which suggests a question: how long an interlock should be bypassed? Therefore, automating process transitions requires strong plant operations input in the development process.
- Because the transition is sequential and dynamic, timing of process steps and interlock changes are critical. These are difficult to validate and verify without both detailed operational knowledge and adequate (proper) simulation routines.
Challenging assumptions
While these assumptions may seem valid at first glance and are certainly expedient, let’s make a closer examination of each, point by point, in light of fundamental process safety concepts proves otherwise.
1. Process transitions are infrequent and of short duration. — Process transitions represent the most volatile time for the process. Variables can change significantly, and the basic process control system (BPCS) may not be capable or tuned to handle such process movements. This is a dangerous time to leave it all in the operators’ hands because of the amount of other things they are required to monitor and execute. The complexity of a transition process (timing, changing thresholds) requires the operators’ full attention. Asking them to provide an additional safety protection layer on top of that focus will increase the level of risk and can be dangerous.
Human factors are recognized as severe limitations to the dependability of risk-reduction factors. A layer of protection must be dependable and auditable. Neither of these characteristics would seem to apply to a bypass situation. During process transitions, variables are changing rapidly and protection thresholds are also subject to change. It is not the time to depend on a less reliable protection layer.
2. There is a lack of similarity between different processes. — While the lack of similarity between processes does increase the difficulty of using SISs, it does not remove the responsibility for ensuring the safe operation of the process at all times. If it is difficult to automate, why would we expect that the operator is going to find it easier to make the right decisions during a complicated transition? In fact, the very lack of similarity between processes is a reason to work out the transition in advance and to make sure the safety systems remain in effect.
At the same time, there are similarities in the control strategies for different processes and we will show that there are ways to deal with them in a consistent manner.
3. There is a lack of similarity between process-transition operation and steady-state operation. — While in many processes, the majority of time is spent at steady state, the more dangerous times are during transitions when variables are changing rapidly and the process is in conditions that the BPCS was not designed to handle. For example, controller tuning may not be adequate for loops during the transitional period. What we are really challenging is the practice of letting the operator do it, because it is difficult to create a SIS that would handle transitions. Exceptions to this are those applications where strict prescriptive standards are applied, such as NFPA 85 and 86.
If we do our job correctly, the time spent on writing and properly training operators in a seldom-used start-up procedure could be better spent on properly designing the SIS to handle transition routines. A properly engineered SIS should consistently outperform a stressed group of operators. We will show later that by using advances in programming technology, it is possible to simplify the design and validation.
4. The process-transition operation is more affected by operational subjectivity and procedures than steady-state operation. — Again, we are allowing “difficult” as an excuse to give up on safety. In reality, the same level of operational input is required to write the procedures needed for a transition routine as to write an automated SIS. There are two real difficulties for getting proper input from operations.
First is the sequence of project steps. It is difficult to get operational input at the software design phase, but less difficult at the procedure writing stage. To do it right, operations must be involved throughout the project.
Second is the lack of communication tools between the operations group and the software design group. It is not easy to translate the needs of process operations into usable SIS code.
5. Because the transition is sequential and dynamic, timing of process steps and interlock changes are critical. — The dynamic behavior of a process is the very reason that it should be automated. It requires a robust simulation routine with the participation of process and operations personnel. However, the idea that we leave such a routine to a written procedure reduces the dependability of an independent protection layer. Since simulation is very difficult with a manual procedure, automation with proper simulation tools is the better answer.
Sequence requirements
Two things are required to define and automate permissive sequences adequately:
● Thorough knowledge of the process and its operation, and
● A set of tools to handle dynamic safety logic.
In the design of SISs, operations management traditionally gets involved in the early stages for the process hazard analysis (PHA) and again during design review to ensure the operational capability of the final design. Operations people are then given the completed unit to start up. Therefore, the bulk of the design data is based on process information that traditionally has been at steady-state conditions. To automate safety functions during critical process transitions, operations must supply significant input along with basic process data during the software design stage.
It is difficult to get the attention of operations people on an ongoing basis. In addition, the operations group and the software design team come from different backgrounds and use different terminology, making it more difficult to communicate the needs of the software design team effectively. Anyone who has gone through a design review with operations, sifting through stacks of ladder logic diagrams, will understand the challenge.
However, if process safeguards are to remain intact during process transitions, it is essential to understand the process that operations will follow, and understand what is practical to expect in the real world. If the safeguards are not implemented in a “reasonable” manner, it is likely that they may be bypassed during actual operation.
Therefore, one of the first steps is to find a common language of communication between the operational and engineering personnel.
A traditional way of looking at process shutdown logic has been with a cause-and-effect diagram. The cause-and-effects matrix was originally derived from Safe Charts in API RP 14C for offshore platforms and is commonly used in the process safety industry for documenting safety requirements. In a cause-and-effects diagram, a set of process deviations, or causes, is listed in rows down the left side and a set of process responses, or effects, is listed in columns across the top. The intersection cell in the matrix defines the relationship between the cause and the effect.
The cause-and-effect diagram has become very popular among process safety professionals because it is an easy method to bridge communication gaps in the SIS design team. The diagram is an easy way for those familiar with the process and operations to understand the logic being implemented in the safety system. Once the cause-and-effect relationships have been examined and agreed to, they can be translated into the safety system program.
A major limitation of cause-and-effect diagrams has been their low ability to handle the type of dynamic safety logic seen during a process transition. Permissive sequencing is difficult to portray in a static matrix. Given that the matrix was originally designed to relate causes to effects with simple intersections, design teams found they needed more options when defining these intersections, not only to make possible dynamic logic but to generate comprehensive validation reports.
Tools for dynamic logic
There are three major characteristics a configuration tool must have in order to be able to handle changing logic. These are:
1. Overrides, including:
- Control overrides as function of process variable (causes), and
- Set up permissive timing (see time dependency).
2. Variable thresholds, including:
- Control relationships between process variables (cause) and process reactions (effects).
3. Time dependency, including:
- Definition of steps
- Limit of overrides, and
- Control of step length (delay, prolong).
Time dependency
In a cause-and-effect environment, the time relationship between the cause and the corresponding effect can take four forms (see graphic). To understand a time-dependent step, let’s consider the purge of a furnace. If the flow rate is constant, then the way to assure complete purge is waiting until a sufficient volume of air sweeps through the furnace’s hearth. In this case, the process variable is time, and a delay post trip will not allow the next step until after the configured duration of the process has elapsed.
Therefore, one should consider four types of time dependency:
- No time function—The effect occurs as soon as the cause is active
- Pre-trip delay or ON delay—The effect occurs a timed duration after the cause is active
- Post-trip delay or OFF delay—The effect is active for a timed duration after the cause is cleared, and
- Timed cause—The cause is active for a timed duration after it is triggered regardless of status.
Variable threshold
Purge in a burner management system (BMS) application is a good example of variable threshold.
Purge must be performed at a predetermined air flow rate, which is usually much higher than the one required for optimum combustion. Therefore, after purging is completed, the air flow rate must be lowered before lighting the pilot or the burners, without aborting the sequence. This defines and illustrates the relationship between different triggering points for the same variable (cause) and selectively defining their relationship with the process reaction (effect). This is done using normal or “N” intersections, and resettable-override or “R” intersections as appropriate. More on this topic later.
Control overrides
Dynamic logic requires that an effect is able to be overridden independently of some causes. For example, in a furnace, we want to trip the furnace when we lose flame so our static matrix shows a flame cause and a fuel valve set (double block-and-bleed) effect. However, on start-up, we need to be able to open (override) the fuel valve set to ignite the burner. In addition, we have to be able to not allow an override based on other causes such as pilot flame.
Intersections of the type “resettable-override” allow for a process reaction to take place (or effects) despite process variable (or causes).
These overrides are time constrained and can only be applied if there is no active process variable (cause), with a normal “N” intersection related this particular effect, allowing for sequence conditioning.
This is, for example, the case of the set of double block-and-bleed valves that define the SIF of a burner. If there is a loss of flame, sensors won’t detect flame (variable or cause), and then the set of valves will block the gas. To light the burner, the action of the flame sensors must be temporally overridden, and this is done with the “R” intersection. On the other hand, the override cannot be allowed if there is no flame in the pilot, and therefore the intersection of the cause “pilot flame” should be of the normal type. In some instances, the sequence might involve turning the pilot flame off after the main burner is on, and this could add complexity to the process. In such case, a new cause that reflects flame in the pilot while pilot valves are open should be created with a normal intersection to the main burner set of valves with a delay post trip to allow transition.
Finally, the duration of an override is another critical point to take into consideration. An override cannot last indefinitely. In the case of purge, for example, the time in which the next step (light the pilot) should be allowed after purge is completed should be assessed during the engineering phase.
A dynamic cause-and-effect matrix
We can conclude then that for a cause-and-effect matrix to be an efficient configuring and documenting tool that allows for validation and verification of a SIS’s logic during steady-state operation, during process transitions, and following S84 standards, it would have the following characteristics:
1. Indicate active causes and effects independently of intersections. For example, coloring columns and rows: red = active, white = inactive, green = reset, etc.
2. Allow the possibility of configuring (delaying and prolonging) when causes become active, as explained in time dependency.
3. Allow the possibility of defining different types of functions on how causes relate to effects (intersections), including independence to override, latch, or complex voting cause architectures.
N: Normal—effect will stay active while cause is active
S: Stored—cause will trigger effect until reset, regardless of inactivity of cause (latched)
V: With override—allows deactivation of effect regardless of cause, and
R: Resettable override—same as V but with latch.
4. Capability to time-limited overrides, and feedback effect actions to causes.
5. Capability to simulate logic dynamically off-line to verify and validate configuration reporting.
Application example
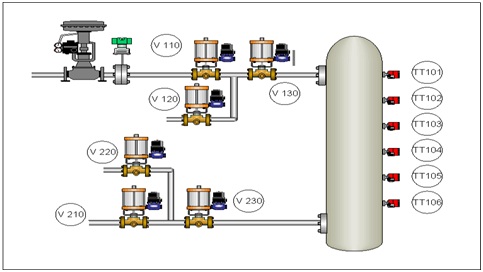
To illustrate the point, let’s consider a very simple example: In this petrochemical process, a hydrocarbon gas needs to be dried by passing it through a reactor packed with absorbent granules. An exothermic reaction takes place in the drier, allowing us to use temperature to evaluate its performance.
If the temperature goes below certain level, 110 °F in this case, it is an indication that the granules are saturated and have lost their capacity to remove moisture. Because of thermal inertia, a 20-sec delay must be allowed before the temperature is recognized as being too low.
On the other hand, humidity is extremely harmful for the process downstream, and the SIF that protects the process has been ruled to be SIL 3 in a level of protection analysis (LOPA) followed by a gap analysis.
The diagram shows how a traditional static cause-and-effect static matrix would look for this application. If four out of six temperatures go below 110 °F, the unit will be taken to its safe condition, that is: V110, V210, V130, and V230 will block, preventing the hydrocarbon from flowing downstream, while V120 and V220 will allow any leakage to recirculate. The “S” intersections indicate that the effect will be latched.
Let’s now consider the start-up sequence procedure as outlined in the operational manual:
Step 1: Bypass all temperature sensors.
Step 2: Manually open V110, V130, V230, and V220, and keep V210 and V120 closed.
Step 3: From the BPCS, increase flow at a rate of 5 GPM (gallons per minute) every two minutes until reaching a stable flow of 30 GPM.
Step 4: Once each sensor has been at a stable temperature above 110 °F for at least 20 seconds, remove bypasses on sensors, one at a time. This should happen within the first 10 minutes of operation or system should be shut down as packaging of granules is shown to be defective.
Step 5: Ten seconds later, open V210 and close V220.
This is a complex operation that places a lot of pressure on the operators’ ability, and it has to happen at the same time they are making decisions on alarms, process value, voting between process values, variables stability assessment, operational bypasses management, and the most difficult of all decisions, aborting if the reactor does not behave as expected.
Let’s now consider an automatic start-up of this process, using a cause-and-effect matrix with all five characteristics discussed above.
Note that all the information is included in the dynamic matrix diagram.
- Causes have a post-trip delay of 20 sec, allowing for the stability claimed on the operation manual.
- All intersections are of the type “R”, for which all effects will be latched when triggered.
- There is an override-reset tag (PB_START) that could be connected to a push button and/or a switch with a key, which should be normally closed to allow diagnostics.
- The maximum time the override is allowed before aborting the process is 10 minutes, complying with what is required by the operation manual. Therefore, the reactor should be stable in 10 minutes or the system will shut down and the process will have to be restarted.
If this program is implemented as indicated by the above dynamic matrix, the start-up sequence would be reduced to two simple steps:
Step 1: Push PB_START.
Step 2: From the BPCS, increase flow at a rate of 5 GPM every two minutes until reaching a stable flow of 30 GPM. This ramp could be done automatically in the BPCS if the safety system protection was in place. The process will be protected at all times by the SIS, regardless of the operator’s actions.
Conclusions and recommendations
The concepts discussed here are not all that complicated and can be reduced for the most part to several simple thoughts:
1. Planning start-up procedures for critical applications can be done with just a little more engineering effort at the beginning of the SLC, when things can be easily changed.
2. Unfortunately, for many critical applications, no prescriptive standards exist that clearly define the proper sequence. Yet there are special applications, such as BMS, that clearly show how to do it. All one needs to do is adopt a similar methodology based on controlled forced overrides limited by fully active SIFs.
3. The benefits of allowing your SIS to stay in control 100% of the time, particularly during critical start-up and shutdown sequences, should be obvious.
4. Performance-based safety standards (e.g., S84) limit drastically the amount of safety credit given to humans since it is very difficult to include human state-of-mind factors into the equations. Thus recommendations are to minimize human participation.
5. Nowadays, there are easy-to-use safety-rated programs (e.g., Safety Matrix) that help make all this happen, without complicated coding and following the verification and validation requirements of the standards.
After all, if it can be written in the manual of operations, it can definitely be programmed in a SIS.
Luis M. Garcia G., CFSE, is business developer for the Americas for Siemens Energy and Automation, Houston, TX.
For more information, visit:
www.iec.ch
www.isa.org
www.sea.siemens.com
Additional reading
IEC 61508, Functional Safety of Electrical/Electronic/Programmable Safety-Related Systems, Part 1-7, Geneva: International Electrotechnical Commission, 1998.
IEC 61511, Functional Safety: Safety Instrumented Systems for the Process Industry Sector, Parts 1-3, Geneva: International Electrotechnical Commission, 2003.
ANSI/ISA S84.00.01-2004, Application of Safety Instrumented Systems for the Process Industries, The International Society of Automation, Research Triangle Park, NC, 2004.
Goble, W. M., Evaluating Systems Safety and Reliability—Techniques and Applications, Research Triangle Park, NC, ISA 1997.
Goble, W. M., Control Systems Safety Evaluation and Reliability, Research Triangle Park, NC, ISA 1998.
Functional Safety Engineering I and II—Exida LLC 2001 – 2004.



