Even after an input/output (I/O) migration, and installing a new distributed control system (DCS) and safety instrumented system (SIS), a southern U.S. chemical manufacturer experienced even more alarms. This article explains how the company solved its alarm management issues while focusing on goals and aligning with industry standards.
Alarm management can become wild over time as a result of changes in process, equipment, and personnel. Such was the case at a manufacturing facility in the southern U.S. where the automation system was controlled by a mixture of a distributed control system (DCS) and programmable logic controllers (PLCs) for compounding units. Over time, the plant’s alarm management had lost efficiency and had grown difficult to manage. The facility leaders knew they had to change the status quo because alarms were dragging down productivity and efficiency.
Alarm management statistics showed that operators were flooded with alarms for 35% of their shift, 25% of alarms were chattering, and each operator had more than 80 standing alarms. Chattering alarms were a significant distraction to operators because they had no significant immediate consequence. Operators were experiencing alarm flooding. However, without context to these alarms, they were difficult to address and were affecting the operators’ ability to do their jobs efficiently.
The facility team decided to perform a migration of more than 9,000 input/output (I/O) to Emerson’s DeltaV distributed control system (DCS) and DeltaV safety instrumented system (SIS). But when the team migrated to the new system, new alarms were generated and the alarm count went up. What happened next wouldn’t have been possible with the previous control system. The facility team decided to tame both the new and the old alarms and created a program to manage the whole alarm system more effectively. New functions in the DCS would make this easier to accomplish.
Setting alarm management goals and building a team
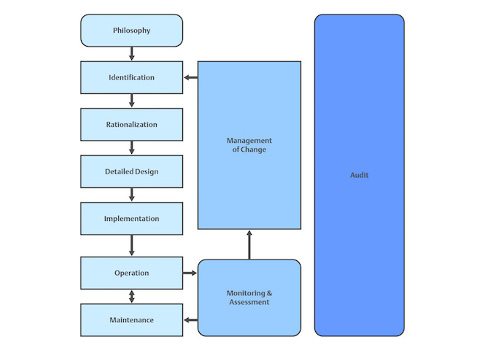
The team focused on goals first by creating a philosophy document that established standards for addressing all aspects of alarm management (see Figure 1). It planned to comply with ANSI/ISA-18.2-2016: Management of Alarm Systems for the Process Industries and align with industry standards, such as less than six alarms/operator/hour, less than 1% flood time/operator, and less than nine standing alarms/operator.
To capture and report alarm metrics, the team installed software that also housed the master alarm database. Automated reports were quickly set up to ensure resources were put in the right places at the right times. The reports also highlighted the work that would be required to reduce the poor metric numbers.
Management: Without support from management, the improved alarm system project would not have gone far. Management was required to support the timeline, approve costs, commit to the time required from groups (especially maintenance), and support a process site owner familiar with the alarm system and code.
Shift leaders: Shift alarm leaders were assigned to enforce the system. They reviewed standing alarms, enforced use of the alarm summary screen, and at each shift, reviewed hard copies of suppressed and nuisance alarms.
Alarm-management subject matter expert (SME): The alarm management SME was detailed-oriented and persistent enough to conduct weekly audits of suppressed/bypassed alarms with the shift, create a plan to fix the issues, and quickly remove the suppression. The SME also conducted monthly reviews with site staff to assess the health of the alarm system, determine the top 10 to 20 bad actors, and create action plans for fixes.
Diverse team: To obtain a broad perspective on alarm requirements, the alarm team included members from many disciplines: a control systems specialist who understood the site’s alarm management, production specialists, senior board operators, and process engineers (who changed periodically to involve experts from each plant area and could help later with management-of-change approvals).
Performing alarm documentation and rationalization
With management support, committed people, and a budget in place, the work really began. The team began to assess risk and rank alarms properly because it had a wide range of backgrounds and could discuss all scenarios related to each alarm. Working four days a week, eight hours per day for six months, the group looked at each alarm—more than 18,000 of them—individually and risk/ranked the different scenarios. If the scenario qualified for an alarm in the risk/rank matrix, the matrix prescribed the alarm priority.
The study showed that most "alarms" did not qualify as true alarms. As a result, the team decided to leave about 5,300 enabled alarms. For each enabled alarm, time delays were documented as was the dynamic alarming code for each enabled alarm.
The newly designed master database documentation now meets the ISA 18.2 standard by including alarm tag, alarm type, alarm setpoint, potential causes, consequences of deviation, corrective action, and allowable response time. The facility had specific requirements, however, that it wanted to meet. Therefore, the master database also includes additional information, such as alarm on and off delay, enable conditions and time delay, disable conditions and time delay, and management-of-change (MOC) notes.
The reduction strategy
Correcting chattering alarms were first on the to-do list. The chattering arose during the conversion to the new DCS because there was not any alarm ON or OFF delays. In the rationalization effort, most of the alarm OFF delays ended up being set to 20 seconds, and the team then decided to set some delays longer on a case-by-case basis. Most of the alarms were rationalized out with a 10-second ON delay, but each case was rationalized individually to determine if a longer or shorter ON delay was appropriate.
Implementation of the ON and OFF delays resulted in a significant improvement in alarm metrics. In fact, chattering alarms were reduced from 25% of the alarm count to less than 4% in the first stage. As the project continued, the chattering alarms fell below 0.25% of the monthly alarm count.
DCS code strategy
Larger issues awaited the team in the next phase with per hour average, standing alarms, and flooding.
Alarms/operator/hour average: When the group initially formed, it had raw data from the startup of the units.
Standing alarms average: After the DCS conversion, the team realized it had unknowingly converted I/O points that no longer existed in the field, thus contributing to the standing alarms. Many more alarms indicated that instruments needed repair. The standing alarm numbers put management support to the test. The maintenance manager dedicated a technician to fix or remove the problem instruments.
Alarm flood percent average: It is very difficult for operators to correctly comprehend all the data and react if alarm flood conditions exist for more than 35% of their shift. After research, though, the team realized the alarm numbers were inflated because of the chattering alarms that were being addressed. Still, the flood conditions easily could have buried important alarms.
To solve the three remaining issues (per hour average, standing alarms, and alarm floods), tools were available in the new DCS as were a mix or custom templates and codes, out-of-the-box functionality, and account management.
The team chose not to use the out-of-the box analog input (AI), digital input (DI), and proportional, integral, and derivative (PID) block internal alarm parameters available in the DCS because the facility’s alarm strategy had too many mutually-exclusive conditions with different time delays. Instead, the team created custom code for these conditions: dc module fail alarms because of an interlock condition, bad process variable (PV) alarm chatter caused by failing instruments, and operator-initiated unit shutdowns that then initiated alarm floods that would last for 20 minutes. In addition, Emerson’s AMS asset management software assisted by alerting maintenance of issues with instruments.
Out-of-the-box conditional alarming parameters were implemented for the AI, DI, and PID modules, which brought a huge improvement in alarm numbers just by adding a 20-second OFF delay to alarms.
The team created higher-level user accounts that allowed supervisors and specialists to suppress and un-suppress alarms. In fact, instead of just suppressing an alarm, they could change the alarm setpoint to a higher or lower value. By allowing the supervisors and specialists to adjust the alarm setpoints, the alarm still will be enabled and will alarm if necessary. A hard copy safety system bypass form and nuisance alarm form are required and reviewed at each shift.
Work continues even after success
The work has paid off. Alarm numbers have significantly improved and the facility is now meeting or exceeding industry-accepted standards. The documented master database of all alarm data includes setpoints, priorities, causes, operator responses, consequences, time to respond, and conditional alarming (see Figures 3, 4, and 5).
Alarm management is a never-ending pursuit of continuous improvement. If left unmanaged, the numbers will start to creep back up. It is important to continue to ask if further reductions can be found in alarm averages, standing alarms, and alarm floods. It also is critical to have a management-of-change process that includes documenting and rationalizing alarms. The process must include a requirement that each new alarm has database information completed and approved before an alarm is added to the DeltaV system (see Figure 6).
Compiled from information provided by Emerson.
This article appears in the Applied Automation supplement for Control Engineering
and Plant Engineering.
– See other articles from the supplement below.



