Consider these best practices for an industrial data operations (DataOps) deployment, according to a company with a Control Engineering Engineers’ Choice Award product.
Learning Objectives
- Understand 4 reasons for a multi-hub data operations (DataOps) architecture.
- Explore how to segment key operations and close network security gaps using DataOps.
- Find advantages in enabling change management and modeling data at the edge using DataOps.
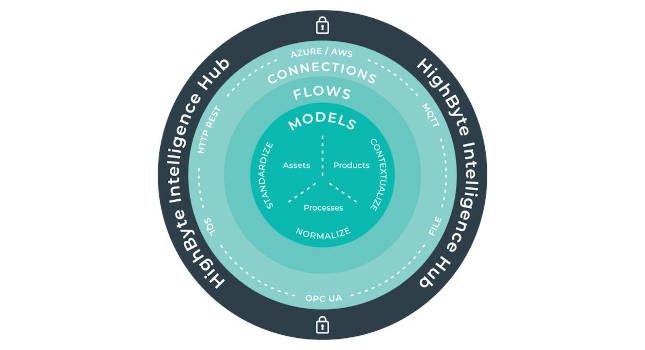
Manufacturers and other industrial companies adopting Industry 4.0 want to make industrial data available at scale across the enterprise to drive business decisions. As these companies connect more processes, systems, and machines, their data modeling and integration needs have become more complex. Industrial data operations (DataOps) solutions provide an answer to this complexity. DataOps is the orchestration of people, processes, and technology to deliver trusted, ready-to-use data to all the systems and people who require it.
An industrial DataOps software application provides a dedicated data modeling management and abstraction layer that helps users streamline their data architecture and reduce time to deploy new systems. As companies have expanded their usage of such software, they’ve begun to implement deployment architectures beyond one in a facility.
Those thinking about investing in a data-modeling solution or upgrading an existing data infrastructure, should consider all possible scenarios before deciding which software is ideal for the organization. Based on customers feedback, deploying a scalable, multi-hub architecture will become more critical as an organization grows.
4 reasons for a multi-hub DataOps architecture
To further illustrate potential uses for a multi-hub DataOps deployment, here are four common reasons to consider a multi-hub DataOps architecture for each site in an enterprise.
1. Segment key operations in DataOps
Facilities often have multiple production lines, work cells or machines. As systems have become more complex and interactions with other systems have increased, maintaining autonomy, agility, and resiliency are critical. Many customers want to segment key functions within an operating environment with unique DataOps hub deployments. That way, changes to one line won’t impact the others. Or, when an operating system upgrade occurs for one production cell, it impacts the work area instead of the entire facility. Some customers want separate hubs for different use cases, such as predictive asset maintenance, production data or quality information.
2. Close network security gaps in DataOps
With automation systems, it’s common for organizations to segment different networks to minimize vulnerabilities. For example, it is typical to shield the controls network from the business and enterprise networks using firewalls, thereby limiting data and allowing data to pass through in one direction. Look for an Industrial DataOps software that supports secure message queuing telemetry transport (MQTT) publishing and subscribing through a firewall. Set up hubs in a federated architecture across multiple secure network zones. Such a federated architecture allows the hub to communicate with systems within the zone and either consume or securely publish data into the other zones.
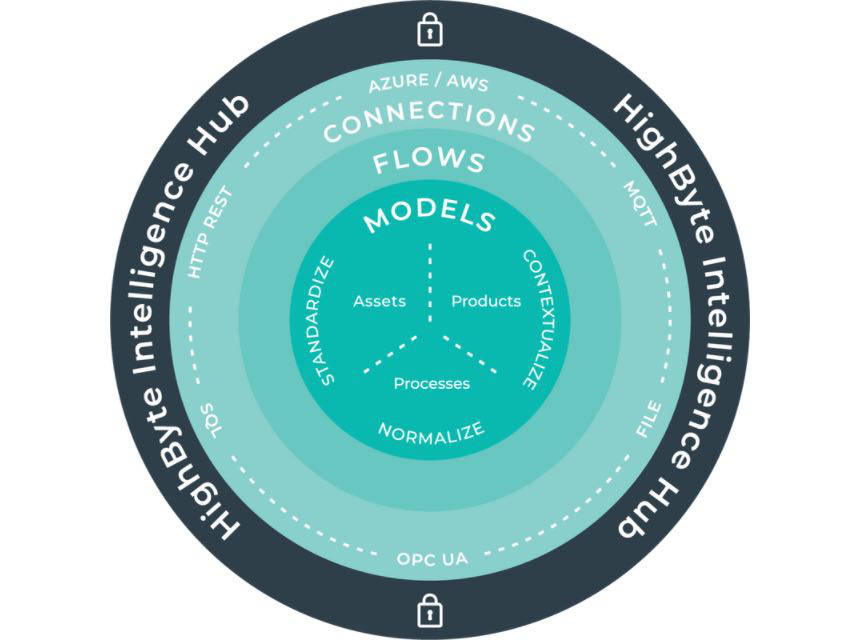
3. Enable change management in DataOps
Operational data is becoming critical for many business functions to perform in day-to-day jobs. Analytics-based systems require an iterative approach and often change as the factory floor is ever evolving with new assets and reprogrammed controllers. Many organizations are establishing development and test hubs to enable rapid design and evaluation of changes for testing prior to production deployment. Within the DataOps hub, users can copy a configuration, push it to another system, make changes to the system, test it out, and then move it to production. That way, when the operation goes live, there’s confidence the system will work.
4. Model data at the edge in DataOps
Execution of real-time analytics in a factory is moving closer to the machinery and is often referred to as running at the edge. In some cases, these analytics are applying machine learning or artificial intelligence (AI) techniques to the setpoint control of a machine where traditional logic-based control could not deliver the results. Furthermore, running closer to the machinery means there is lower latency and lower risk of missed data. A DataOps hub serves as the middleware between the device and the analytic software and runs on an edge gateway. It ensures the data is collected from the work cell or machine in a consistent and standardized manner, allowing the deployment of the analytic across similar machines quickly. By leveraging a site license and container-based deployment, a hub can be cost-effectively deployed at an unlimited number of these edge nodes in the factory.
A lesson learned from the pandemic, is the need to be nimble in today’s uncertain environment. Changes happen fast when consolidating production, retooling product lines, or reconfiguring an operating environment. A multi-hub industrial DataOps deployment minimizes overreliance on one system, so organizations can implement changes faster with fewer disruptions to operations.
John Harrington is chief business officer at HighByte. Edited by Mark T. Hoske, content manager, Control Engineering, CFE Media and Technology, [email protected].
KEYWORDS: DataOps advice, Engineers’ Choice Awards
CONSIDER THIS
How are you using a multi-hub data operations architecture to improve operations?